- Home
- Resource library
- Webinars
- Preventing Kubernetes Misconfigurations Using Automated Policies w/ Datree
Preventing Kubernetes Misconfigurations Using Automated Policies w/ Datree

Itiel Shwartz
Co-Founding CTO @Komodor

Shimon Tolts
Co-Founding CEO @Datree
The widespread adoption of Kubernetes and microservices has opened the floodgates of innovation by allowing developers to deploy continuously on epic scales and at an accelerated pace. However, moving fast often involves breaking things, and when it comes to the intricate and distributed architecture of modern K8s-based systems it’s much harder to put all the pieces back together while still moving forward.
The secret to reliable cloud-native software lies in the foundations. That’s why it is so important to invest in planning your infrastructure before you build it and to implement the right tools for prevention, mitigation, and troubleshooting.
[Beginning of transcript]
Yonit: Yes, now we are live. Hi everyone, it’s great to see you all here. I’m Yonit Tannenbaum head of marketing at Datree. Today, we have the pleasure of hosting Komodor’s co-founding CTO Itiel Schwartz and Datree’s co-founding CEO Shimon Tolts. Also with us is Udi Hofesh head of community at Komodor. On this webinar, we’ll talk about Kubernetes misconfigurations and how to avoid them. We’ll start off with a high-level overview of CI/CD best practices through Itiel’s story of how he built a cloud-native company, in the middle of a global pandemic no less.
Afterward, we’ll switch gears to hear from Shimon for a more practical guide on how to implement automated policies for Kubernetes using Datree’s platform. And finally, we’ll conclude the event with a short Q&A session. So, before we kick off let’s introduce our speakers. Shimon Tolts is an AWS community hero and runs the largest user group worldwide. When he managed the software engineering infrastructure department for 400 engineers at Ironsource, he experienced a significant pain point that led him to co-found Datree. Which is an automated policy enforcement tool for Kubernetes.
Itiel Schwartz started out at eBay, formerly Forter. Then went on to become the first developer at Rookout. He is a backend developer turned DevOps and an avid public speaker. Today, he’s leading the team that’s building the first-ever Kubernetes-native troubleshooting platform at Komodor. Itiel the stage is yours.

Itiel: Can you hear me.
Shimon: Yeah, so it’s nice to have you here Itiel.
Itiel: Thank you. Pleasure to be here with Shimon and the three folks. So, hey everyone, I’m going to talk a little bit about building a CI/CD native. Like the best practices for CI/CD, for cloud-native applications. So, let me start with our own journey of building Komodor and basically trying to use the industry best practices while doing so. For those of you who don’t know Komodor, we are a Kubernetes troubleshooting platform. Basically, we allow developers and DevOps to troubleshoot easily when they are running on a Kubernetes platform. We started Komodor like a year ago. Sorry, let me tell you a little bit about myself. I’m the CTO and co-founder of Komodor.
Here you have my picture with my younger daughter Ella, which is currently sleeping and I really like Kubernetes. So, I’m going to start by talking about how our journey started. Basically, we knew we wanted to solve a problem in Kubernetes. We built our own tool for our entire system on top of Kubernetes. And when we started the company, we had a group of very talented and knowledgeable engineers. And we wanted to take the right decision from the get-go in order to make sure that developers can move very fast in Komodor.
So, the CI/CD was one of our main like focus points even when the company was super young. Because we know it’s something strategic to us to be able to develop and to deploy to production rapidly. I’m going to focus now on the decisions that we took, the good decision and the bad decision all in one. So, I’m going to skip this part and I’m going to speak only on the CI/CD part. So, I’m going to start with the base premise that, production is the only place that matters. Like you know a lot of people are doing the optimization before going to production and then when the application is deployed, they find out a lot of bugs and issues and so on.
In Komodor, we believed in being fully CI/CD from day one. Not because it’s the new hip thing, but because we believe that we can only test, really test, our code in production. Also, our goal is to bring as much value as possible for our users for our customers. And in order to do so, we don’t want to have features that are stale on a feature branch or something like that. We want to move rapidly and to deploy to production dozens of times a day without being worried. Basically, I can say that the time that we spent on the CI/CD part already has returned itself and then some.

I will say that the main test for me as a CTO and for our team is the ability to feel safe when you merge to master. If your developers are or if you are a developer that managed the master and every time you merge to master, you are afraid that you are going to break everything. Or maybe you count on the QA to help you. You are doing something wrong. And the main thing here is A publish fast and B, do it without being afraid. Mainly, have like a real insurance in your test pipeline. So, a little bit about the tools that we use. The first thing we use is we are running on top of Kubernetes.
We are really big believers in docker, and we took a not-so-standard approach of making sure everything is part of the docker build phase. And that means for those of you who don’t know docker multi-stage build, it basically means that the first step is testing the code. And the second step is taking the artifact that was already tested in the first step and using them as the base of the production image. This allows us to use docker caching capabilities for making sure that we don’t run the same test twice. So, a normal docker file in Komodor looks like a “test-build-test-build” and then removing all of the unnecessary files to make sure the image is as slim as possible.
At first, we started using CircleCI. For those of you don’t know it, it’s a great CI/CD. Like I think it’s the most popular SaaS solution for CI/CD. It was very easy to get started. They have really good guides and I think overall if you are starting to build your own company, it’s a great first choice. After a while we moved to Buildkite, the main reason for moving to Buildkite, for those of you who don’t know is a new CI/CD tool. Their main focus is they give you more flexibility on running your own code, your own infra running inside your Kubernetes cluster, very easily. Because they are using a very slim go agent to do all of the heavy lifting for them.
So, we moved from CircleCI into Buildkite mainly because of the docker caching capabilities. We are just releasing a blog post about that, that is written by our great Ronna Hirsh, who led the move from CircleCI to Buildkite. But the main advantage is the docker cache capabilities, it’s cheaper and also it allows you to write your pipeline code not as YAML but as Python. So, by moving from CircleCI to Buildkite, we moved from a six-minute deployment process into less than one minute. For most flows, it was around like 20 seconds. It also allowed us to get rid of all of the boilerplate code.
By using python instead of YAML, we can write like one for loop to go and do the same stages for all of our microservices. And this allows us to remove like hundreds of lines of YAML code into six or seven python lines. So, it was a great move and we’re really happy customers of build guide. I will also say the docker thing like it simplifies a lot of things by doing the docker, the testing as part of the docker build. You are gaining both the cache part, but also you gain the ability to run the same code both on your CI/CD for us in BuildKite and also in case something failed you can simply do like a docker build and gain the same assurance that things are running the same.
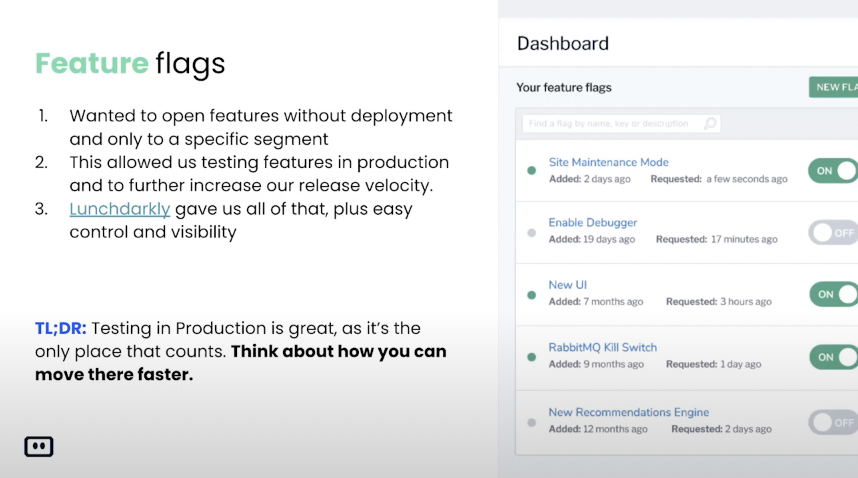
So, it’s really a great option and I will say that the main thing that we learned here is don’t be afraid of experimenting with new tools, switching, like from CircleCI to Buildkite. We also tested a lot of other tools, but overall, it was really a smooth sail with Buildkite. The second thing that we are very strong believers in, it’s not really a CI/CD move but more of a rapid deployment. We are big believers in feature flags. Like I said, the only place that really matters is production and we wanted to have Feature flags basically almost from day one. So, we can deploy our code, test it in production for a specific user. Like basically we’re the beta testers because we are heavily using Komodor ourselves.
We are our own beta testers. And by using feature flags, most of the features are starting with a very like small exposure to Komodor and then we expand it to other users. And we decided to use LaunchDarkly mainly because it’s very very easy. It’s a little bit expensive, but I think it’s worth it for managing the feature flags and the audit part, and everything else. And again, I can say that using Feature flags and Buildkite allows us as a company to release new features to our customers within a couple of days per feature, instead of weeks that we normally should have if it wasn’t for the feature flags and are very rapid and good CI/CD.
I will now speak a little bit about general tips. I think it’s very important mainly for people who are less experienced with cloud-native CI/CD or basically building your own CI/CD pipeline and platform. So, I think making sure all testing strips can be tested locally is one of the most important but neglected areas of building a good CI/CD process. For all of you who run like Jenkins or even CircleCI, what happens usually is you have some sort of bug inside your pipeline code. And this really sucks, because a lot of the time you can’t really test it locally. And then you see people like doing hundreds of commits triggering their pipeline, trying to find and fix the bug.
So, the ability to run your code locally is super important and I really can’t stress it enough, how much time it saved us that we can run a full cycle of testing code locally and troubleshooting and testing it. So, this is like the first thing. The second thing is to try to use new technologies to make things even better. We are currently using Docker compose for some parts of our testing capabilities, but we are doing migration from Docker compose into KIND. Because we are like a Kubernetes native company and because KIND is a very, for those who don’t know KIND, it’s like Kubernetes inside docker, one docker image that runs Kubernetes. And then you can replicate your entire like Kubernetes environment on top of that KIND cluster and do your test very similar to what production looks like.
So, by moving from Docker compose to KIND, we can gain tests that represent our production system a lot better. The third part is Testcafe. For those of you who have applications that also have a website to it. So, like web is a little bit tricky to test. You can test it locally with different tools but in order to make sure your application is really running. I believe you need to check both your front-end code and your back-end all in one place. And by using Testcafe to run after staging and after production we give our developers a lot more confidence in the release into production. Because it’s not only that the backend team is not afraid that they are going to break the back end and the frontend team. We run like with the full stack.
But like as a concept, people don’t need to worry about the integration part because A, we have integration test and B, we have a full flow that represents a Komodor customer inside each time before we release to production. And this give us a full system guarantee that things work as expected. I will say building a Testcafe automation can be tricky sometimes because it has its own ramp-up. It’s not as easy as writing a normal unit test, because there is the browser part and browser testing. It can be difficult, and the main thing that is difficult is the signal to noise. A lot of times it failed. but you don’t really understand why it failed.
I think Testcafe from our experience of using Testcafe site ref, I think Testcafe is the best choice, but I do know that there are other good options. I can also mention Testing.io which are automating even more parts of this process. The fourth and I think the most important one and again something that is a bit neglected when we are talking about CI/CD pipelines is adding tests after each postmortem. Like it doesn’t have to be after each postmortem, but it should be something very obvious for everyone. We want the ability to make sure that it’s safe to deploy to production. What usually happens? At first, if you deploy something to production no one really looked it in the eyes, because we are fully CI/CD and everything is great. But then something happened, like your production crashes, usually report a very big incident or like a bug.
And you’re starting to get a little bit afraid, and that’s the time when people are asking themselves maybe we need a QA or maybe I need to add some steps of manual approval before I deploy to production. So, we believe strongly in moving fast and breaking things. And in order to achieve that, you need to be first able to trust your team that you are not going to break too much things and once things break you can regret and fix them easily. And the second thing is to learn from those best incidents. Meaning after you had a production issue after a customer complaint, you need to ask yourself, ‘what tests should I add.’ Another very important thing here on for like adding tests after a postmortem, it shouldn’t be the DevOps’ responsibility or something like that.
We believe in full ownership, the dev should be responsible for everything, and if a code they wrote caused a big massive issue or a bug. Then they don’t really need to be afraid and that it will happen again because they are going to a test making sure things like that won’t happen again. So, to conclude everything here, I will say that you are going to spend a lot of time setting a good CI/CD pipeline. Even for experienced developers and DevOps, this thing takes time. It is a process and you should go into it investing time in those areas, knowing that it’s going to pay off even at a cost of a week of a developer’s happiness.

I will say that (you should) treat it as a production code and make sure it’s easy to test. Like you won’t release a very big code to production without testing it. The same goes for CI/CD pipelines. And the last thing I’m going to say is make sure you always iterate. Like tests can’t freeze over and don’t change as your application changes. It’s something that should be dynamic, should be alive, and should rapidly change. I’m not sure like I have any questions here, are there any questions? I guess not.
Shimon: I can see that Mark has raised his hand. Do you have a question Mark? Do you wanna ask it? No, okay.
Itiel: No questions. so, I think I’m going to move the floor to. It was in your pocket, no problem. I’m going to move it now to Shimon to talk a little bit about misconfigurating Kubernetes, something that happens a lot.
Shimon: But I have a question. Did you consider using Cypress for the tests?
Itiel: I did use Cypress. Testcafe at the time was more stable and when we tested it. I did hear from our customers that Cypress really improved, but yeah like we kind of love Testcafe. It just works, so we don’t think about moving away from them.
Shimon: Sounds great. I like it that everything is like infrastructure as code or code and then everything is revision. Then you can work on everything and I really support that. We also believe in that.
Itiel: Yeah. And Udi you know I don’t think I’ll take the five minutes, there are other things like other general tips to build a cloud-native company. But I think it’s less related.
Shimon: Okay, so hold on Itiel while we’re going to do a poll. And I want to talk to you about it as well. So, I’m going to launch a poll and the poll is about Kubernetes. The Poll is going to ask, the first question is do you run a Kubernetes in production workload? Like, are you a Kubernetes administrator? For some reason, I see it is untitled question. But the first question is, are you an administrator? And the second question is, where do you run your Kubernetes production workload? So, this is my question to you Itiel, while everyone is voting.
Itiel: We’re using AWS, in the past I used GKE. I can’t say that it works. I think GKE is a lot faster than the AWS solution, but overall AWS like the other services it’s just better. Using like the other things such as RDS, SQS and so on. So, for like a Kubernetes native solution, I think GKE is also a very good option. But overall, I used AWS like three years ago when it was beta. And I use it now and I can say that like the solution has zero issues since we started like more than a year ago. So, very stable and very nice.
Shimon: Can you stop sharing please? So, do you use EKS and do you run your own EC2 nodes? Do you run the EC2 managed EKS or do you run on Fargate? And then I will tell you what we do.
Itiel: Well, we use normal like EKS on like EC2 instances. And we don’t have a huge workload, so it works quite well for us and. So yeah, EKS for normal EC2 instances.
Shimon: Cool, so we also run on EKS on AWS mainly, and we use actually Fargate which is really nice. Because you don’t need to manage the EC2 instance, you don’t need to worry about you know the security patches and everything. Cool. So, I’m going to end the poll and I see that the vast majority of people here are eight are Kubernetes administrators and it’s interesting. So, number one result in terms of where do you run your production out a workload is actually ‘other’. So, let me share the results. Do you see the results?
Itiel: I can.
Shimon: Yeah, okay. So, it’s interesting most people say ‘on-prem’ or ‘other’ and the second one is ‘AWS’. The third one is GCP, and then there are no Microsoft fanboys here. Which is okay you know we’re not judging. Okay, so I’m going to share my screen now and I’m going to go deeper in Kubernetes. So, this is going to be a very hands-on discussion and presentation about Kubernetes. Hopefully, you can see my screen. Just so you know you can use the Q&A tab and ask questions and you can also use the chat. I’m reading the chat and also Udi and Yonit are helping us so just so you know.
Cool. So, my name is Shimon Tolts. I am version 32 in the world, and I’m the co-founder and CEO of Datree. And together with that, I’m very active within a different community, too much I would say, a CTO club, I’m leading the CNCF cloud-native Tel Aviv branch and I’m also an AWS community hero. So, I get to talk with lots of startups, lots of companies. This is how I know Itiel and their company and we really love working with them. So, today I’m going to talk to you about how to prevent Kubernetes misconfigurations from ever reaching production. Which is actually the mission of what we do in our company. But I will show you also how you can do that by yourself also using open source solutions.
So, this is what we do in Datree, we are an open-source. You can go to Datree.io at GitHub and we integrate very well with different ecosystem tools like some that Itiel talked about. Like Circle CI and the GitHub, Helm and more. So, as we said policies is what we do and I’m going to talk about some unpleasant postmortems that happen to companies that crash their production and caused major issues. Then I’m going to talk about how can we actually prevent that from happening.
So, first of all we have the failure stories, the postmortems, talk about the policies and then we look at the different tools that we can use in order to automatically avoid it. So, number four is an outage at a very small store called Target, which is obviously one of the largest in the world. And the Kubernetes failure event that they had is actually a cron job that spawned more than 4,000 pods, because it was misconfigured. And the concurrency policy was allowed and this is the configuration that happened. Overall, it doesn’t sound to be too problematic, but you need to verify your concurrency policy and it is very easy too, it’s like image pool policy always concurrency policy always. It’s something that you don’t even remember and what happened that it constantly ran and spawned a lot of pods for them.

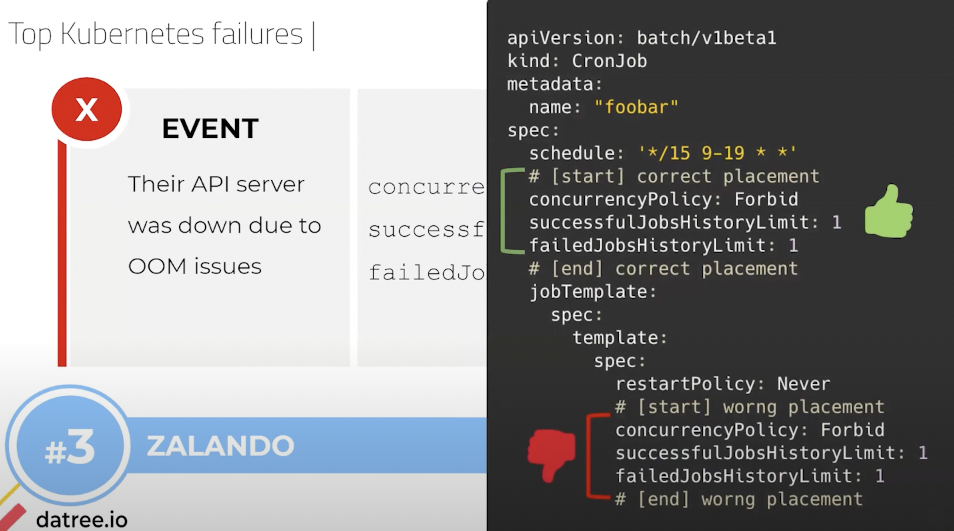
The second one is Zalando, which is a huge retailer from Europe, much like Zappos. And the problem that they had is that their API server was down, because it reached an out of memory status. Now you can ask yourself, but wait what’s the problem, you can just put limits. Yeah, so what happened is they accidentally put the configuration on the spec level. Sorry, inside the spec restart policy level and not only on top. And what this caused is, this caused again a loop that also ran and it caused it to spawn more and more and more and more and more events. And all of this happened because they accidentally put it in the wrong place in the YAML. Even though they had the correct one on top, they also put it on the bottom.
This is also a common and very simple mistake that people can make. So, always ensure that the Kubernetes structure file is valid and that you verify it. And we’ll talk about this in a moment. Another issue is that a smaller company you know not everyone is a Zappos or Zalando. So, Blue Matador, which is a smaller company. So, their entire cluster was down due to out-of-memory issues. And the thing is they did not specify requests and limits especially to third-party services that they did not know how they are going to behave. What happened is that when you have a noisy neighbor that takes up as much memory as it wants, maybe it’s like some java service that just sucks the life out of your memory and it just accumulates everything. Then Kubernetes is going to run out of memory and start killing your workloads.
We’ll talk about how to put memory limits and requests. And the third one is yet Target again and their entire cluster was down due to an ingress misconfiguration. Which is they specified that the entire host should get the traffic. And when you put host as star, it overrides your entire configuration and can cause your ingress to go down. Now what am I trying to say here so when you look at this like how are you supposed to remember that you need to put something at some location and that the concurrency policy should not be allowed always. And it’s really really easy to make those mistakes. You know even if you’re an experienced Kubernetes administrator, you want something automated to run and help you make sure that you’re making the right thing.
And all of those mistakes that you saw happen multiple times to many companies some of the great companies in the world. And even they got those production outages and issues happening to them. So, how are you to prevent it? What can you do in order to make sure that those mistakes don’t happen again? Because on the one hand, you could say, ‘Okay, so now on the Ops team, the SRES, the DevOps will review all of the Kubernetes YAML or Helm charts changes. But then you know the developers; they want autonomy, they want to make changes and ship them into production. And the DevOps engineers, they don’t want to babysit developers to make sure they did not forget to put a star or did put a star.
I think that the right solution for this is a sort of a guard rail, where on the one hand the developers are free to go and change the way they work and do whatever they see fit. But within certain ground rules, guardrails and certain rules that they can follow that will make them feel safe. And know that if they’re making a crucial mistake, the system will help them. How can you do that? So, I’m a big believer in automation. If we look at the development pipeline, so it’s a very very abstract pipeline I’m showing here. So, you can develop your code, then you have your CI pipeline which is usually build test integration tests and so on. You have your CD pipeline which usually creates the artifacts, sends them into your artifact store and prompts your production to pull the new artifacts and promotes different versions.
Finally, you have production which as we saw most of the people here run Kubernetes as production. So, in those areas what you can do is you can incorporate a tool that will help you find mistakes way before they reach production. Because once you find the mistake and once it already reached production, it’s way too late. And you want to fix it beforehand. More importantly you want to give the ability for developers to understand that there is a mistake and that the mistake can be fixed from their side and they don’t need to wait for anyone else. So, here I’m showing three tools. All tools are based on OPA, Open Policy Agent which is a CNCF graduated project from last month.
So, it’s a very big celebration. By the way, it’s now in the same level as Kubernetes as a CNCF graduated project. So, what you can do with Conftest and I will get into it deeper in a second is actually as the name states Configuration Tests. And you can write regular policies that will scan the manifests and look at the configuration and determine whether the configuration is valid or not. And you can run this in your computer, you can run this in your CI/CD.
Next, you have gatekeeper which actually runs on the cluster as an admission webhook. And this admission webhook inspects every request that the cluster receives from kubectl and it inspects whether it is valid in order to be performed. It also uses regular policies, and if let’s say I want to schedule a workload that has no memory limit or has no liveness probe, it can deny my operation similarly like a hook in Windows or Linux can do. A system calls and we’ll just block it. Now of course this is very far into production. And it’s like a last line of defense but it is also an option.
Finally, you have Datree that comes built in with policies that are predefined. So, you don’t need to write all those policies by yourself in regal. You can if you want but it comes as predefined and also allows you to have a centralized management solution. So, with Conftest, you can actually go and write tests against structured files. It is designed to run on a local NCI environment and it is built on top of OPA. So, anything you do and write for better or worse it is in OPA, which is a declarative language. And there you can specify the tests and then you can very similarly to how you run tests on code. You can run for example Conftest, test deployment YAML. And as you can see deployment YAML containers must provide the app label which is a test that checks that the manifest YAML actually has a label by the name of app.
This is very good, once you want to assign different workloads into different groups and cost centers and run even more automations on top of it in order to know what assets and resources does it belong to. So, we talked about the different misconfigurations that you can do. And what we offer and what I encourage you to go and see it is open source, you can check our code, you can put a pull request, you can find our bugs and feel free to jump in. so, we provide a CLI solution for policy enforcement. So, it is also designed to run in your local environment and in your CI environment. But the main difference with Conftest is that it is centralized management. So, it is managed from our centralized Datree SAS.

So, let’s say you have a hundred developers, you can change the policies and dynamically allocate new policies that will auto propagate into all of your developers and all of your CI operations automatically from the platform. As if you use Conftest you will have to go and let’s say you have 100 repos, you’ll have to do 100 commits and change the policy or create a mechanism that will download it from S3 and start managing. And it’s a whole cycle of work that you have to do in order to create this centralized policy management. Another thing is that when you start using OPA and Conftest and Gatekeeper, it is a great infrastructure but it is like unit tests. You need to write the tests, and one of the problems is that you don’t know what you don’t know.
So, there are companies like Datree who read 100 postmortems of different companies and found the most common mistakes and misconfigurations that happen and we provide that as a built-in policy. Another approach that you can do is when you have an outage, you can codify the test and then prevent it from happening again. But I think that being proactive and detecting it ahead of time is even nicer. So, the way the solution works is very simple. You go to Datree.io and it’s just a one-liner. Datree curl, you curl a get.datree.io and it downloads and installs the solution. And then you just run it against a Kubernetes manifest or Helm charts.
In terms of policies, I wanted to go over some of the policies just you know for the sake of interest and to show you some of the policies that most of our customers use. So, make sure that you actually have a pinned version for your container that you’re pulling. Many people are pulling the latest tag in a docker container, which is very funny to me. It’s like going to the casino, every time you build this you don’t know which version you’re going to get. And then when you have an issue and you look at your code, you see that you’re using let’s say Ubuntu latest. But then you’re asking yourself, ‘But wait which version is actually running in production. I don’t know, I need to check at the date that it was built. And then at this date, what was the latest tag. I need to try and assess what was the version.’ Which obviously is very hard and it’s just needless and it’s not good.
Ensure that the cron job scheduler is valid. We talked about this and I showed you several production outages via misconfigured cron job. Ensure that all containers have memory requests and CPU limits requests. Sounds so trivial sounds so simple, but most people do not have that. And this is actually one of the most important things is to use resource quota. Because otherwise you know it’s a shared instance and one app can kill the other. Another interesting thing is you know make sure that you have labels you know owner, department and so on.
Also, the final thing I’ll talk about here is making sure that you’re not using deprecated APIs. Which is also one of the common things where you want to upgrade your Kubernetes cluster. But then you’re faced with the question of okay, so let’s say I update it. How do I know if all of the YAMLs that are operating against my system are actually using non-deprecated versions? Because if I upgrade it, they might stop working. So, now I need to go and I need to search my entire GitHub and find all the Helm charts or Kubernetes YAML. Understand which API versions are they’re using and then map them with the API versions that are going to be deprecated in the version that I’m upgrading to and do this delta.
Of course, this is not rocket science but it’s just not your core business. You could do this but the question if this is what you want to focus on. So, as I said we provide a centralized solution so you can actually see all the tests that are being run in one centralized place. You can see we’re checking that the YAML is valid. We’re checking that the schema of the Kubernetes manifest is valid to the version of your cluster. So, it’s a schema validation, and then running a set of different policies of course you can enable or disable some of the policies, exclude them for certain workloads. You are free to choose whatever you would like.
And finally, we provide rich documentation and you can go into hub.datree.io. I’ll write it in the chat and we actually list most of our policies there. So, feel free to copy and if you want implement even those policies by yourself, we share it with the community. Every policy we say, what is the policy? How does it fail? what is the condition? What is the problem. How do I fix this issue? And we explain everything from A to Z. So, be our guest and use it as a knowledge base for you to get educated and learn more on how to not make production mistakes with your Kubernetes workloads.
And with that, my final slide I encourage you to go and look at our code it is written in go it is a multi-platform. We already got some pull requests. Someone made the pre-commit hook for their git and submitted it which is really cool. You can run it in your CLI on your laptop. We’re working on a kubectl add-on. VS code add-on, we’re looking for people to add it as a vs code add-on. So, if you would like so that every time you save a Kubernetes, YAML or a Helm chart, it will actually run the checks. And it’s not that difficult and it’s really cool. So, I encourage you to go and look at the code that I and my friends at Datree wrote.
So, it’s all about the policies. And with that, I’m going to head out in terms of questions. I use Helm charts, does Dathree integrate? Yeah, so no problem. You can use Datree with Helm. We have a helm plugin, so it’s like Helm, Datree test and it works. Okay, Itiel I think you have a question.
Itiel: Yeah, Great talk Shimon and I love the example of the issues.
Shimon: Thank you.
Itiel: Yeah. So, what integration do we have? Basically, Komodor I didn’t really talk with about us too much but I will say that our claim to fame is collecting all of the changes that happen in your system. If it’s Kubernetes, if it’s landscaping, if it’s any other integration such as like Datadog, Centripetal and so on. And build for each service in your system for comprehensive time and included in both everything that changed and how did it impact the service. So, regarding what integration do we have, we currently have like 15 integrations. (out of) Which Kubernetes is the basis. And we have GitHub GitLab Bitbucket periodicity option and so on. But also tools such as Datadog and New Relic and LaunchDarkly and other configuration tools. So, we try to integrate with everything inside the Kubernetes ecosystem.
Shimon: So, if I have a Datadog for example, we’re using Datadog. So, it can just give you access to our account and then you can pull data.
Itiel: Yeah, and it just works and you can see for example that you had a deployment. And after like five minutes a Datadog alert just got triggered and then you can revert the issue very easily. So, yeah Datadog is like the number one integration we have.
Shimon: I love Datadog. I think they’re doing a great job. Okay, question, where is the best place to integrate a solution? Everyone’s asking about integrations. Integrate the solution with Datree within my dev process? So, like I said you it’s a very simple. So, our solution it’s just the CLI. It’s open-source. I’ll just show you really briefly. This is the GitHub okay, as you can see. And you can just scroll and download it. You can run it in your CLI. You can put it as a pre-commit hook, you can put it in circle CI, and so on. We actually have examples here for all of the different services.
Okay, I see more questions. Dima; apart from checking policies Datree checks versioning issues. When you say versioning issues, so we check, if I understand correctly, you’re talking about a different Kubernetes version. So yes, you can actually specify for Datree which version of Kubernetes are you running or you want us to check against. And then when we execute the tests, we will do a schema validation and we will tell you for example if you’re using a deprecated API for this version. We will tell you, ‘Hey, this API is like V2 beta you know is not going to work anymore and we’re going to fail it. So, I hope that answers your question.
Cool, Dima. Okay, let’s try to follow the questions. Is there an autofix for versions? No, not yet. I’d love to hear Omer Livne from you, how you would like to see an autofix. Because there are different options, I would love to hear it from you. Auto formatting? No, you know it’s YAML use VS code. It will auto format it.
Itiel: YAML formatting is hard for anyone who did a lot of Helm. It is problematic from my experience.
Shimon: So, yeah, I agree. So, Itiel you have some more questions here.
Itiel: How is Komodor different than Argo CD or Grafana? Argo CD, as its name implies basically allow you to deploy to Kubernetes very easily and Grafana allows you to monitor things such as like metrics, array latency and so on. What Komodor focuses on is changes. So, basically everything that changes in your system. And a change can be something as simple as changing the directory name. But it can also be something like changing of an image from one version to another that also implies changes in your source control. Komodor basically takes all of those changes from all of your different systems and puts everything in a very nice and easy to use timeline.
So, you can go back in time understand what changed, you change it and then solve issues a lot faster. Instead of going to different tools and you know like asking who changed what when why and so on.
Shimon: Wait, you have another question. How is Komodor different, okay.
Itiel: No, I think you have one from Omer.
Shimon: Yeah. I see that the free plan for Datree includes one thousand invocations. Will that be enough if I have one Kubernetes customer? Yeah, so we have a very generous free tier. You can just sign in and use it. It includes 1,000 invocations and invocation is when you run the test. So, you can test against one or 1,000 files and it’s one invocation and we give you 1000 invocations. So, if you have one cluster and five projects, no problem. Like most likely in order to suppress like one thousand…our free tier, you need to have like dozens of engineers and dozens of Kubernetes projects.
So, like if you’re a small startup and so on, we built our solutions to just be free for you. And if you need more, feel free to talk to me and if you’re like a non-profit or whatever shoot me an email and we’ll help you. So, Omer I’m talking about API versions V1 beta for V1, I see. Okay, Omer, can you drop your email address to me personally and I’ll get back to you? Regarding that, I want to check it from my side. Because I understand what you’re saying, it makes sense to me. I just want to check it with the product team and give you a response. I think if you are from Emo beat, then I found you. Okay, our time is coming to an end. Thank you everyone for coming. I really enjoyed this Itiel, it’s really nice.
Itiel: Me too. We can also promote that we are talking together in Yalla DevOps next week. So, we can promote that as well. If anyone wants to hear more from me and Shimon.
Shimon: They’re saying we’re on the tour, this is the two of us.
Itiel: Yeah, this is the tour.
Shimon: Okay, amazing cool. So, thank you very much. We will send the recording to the people who registered, so don’t worry. We’ll send it to you, and have a nice day, evening, morning wherever you are in the world.
Udi: Bye everyone. Thanks for coming