- Home
- Resource library
- Webinars
- Take a Walk On the Safe Side: Using Feature Flags w/ Sentry
Take a Walk On the Safe Side: Using Feature Flags w/ Sentry

Itiel Shwartz
Co-Founding CTO @Komodor

Dustin Bailey
Solutions Engineer @Sentry
Udi: Okay. So, let’s begin. Hi, everyone. Nice to see you all here. Welcome to the “Take a Walk On the Safe Side” webinar, where we’ll talk about using feature flags with Sentry and Komodor. Say hello to our panelists today, Itiel Shwartz —
Itiel: Hey, everyone.
Udi: — founding CTO at Komodor, and Dustin Bailey, Solutions Engineer at Sentry. And also with us today is Rahul Chhabria from Sentry as well. So, to start things off, I’d like for you to talk about how you use feature flags at Komodor and Sentry respectively, and kind of share a bit about your experience using feature flags.
Itiel: Yeah, sure. Dustin, do you want to start it?
Dustin: Sure, yeah. So, feature flags are used at Sentry when it comes to rolling out new features in the development process to internal users, to early adopters, and eventually, when those features have proven to be stable to general access. I think what we’re going to focus on today is how anyone on the call, that’s already using feature flags, in combination with Komodor and in combination with Sentry can leverage some features within each platform to effectively accelerate decision-making when it comes to debugging issues related to feature flags. And also using some very helpful features within Sentry to also accelerate decision-making and perhaps declutter decision-making when it comes to identifying which issues are specific to which particular set of feature flags or individual flags themselves.
And I think the one feature I want to highlight at the outset of this is Sentry tags so you can set custom key-value pairs, via the SDK within Sentry across multiple platforms. And this can be very helpful for going from, say, a service level within Komdor into the code level for a specific project. And actually identifying which feature flag is associated with a particular issue that you’re looking at now having traced it from observability at the service level down into the code level, and now you can effectively turn the feature on or off, depending on how that feature is either being adopted or experiencing issues. Over to you, Itiel.
Itiel: Yeah, sounds good. Thanks, Dustin. So, Komodor uses feature flags like, first of all, I’ll start with a little bit about what is Komodor ‘cause I don’t think everyone here knows like they do with Sentry. Komodor is a Kubernetes troubleshooting platform. Basically, we allow developers and DevOps to troubleshoot issues they encounter in their Kubernetes cluster very easily. What we do is we track the state of the cluster of the services that are on top of the cluster combined with the changes that happen across your system to give our users a full single pane of glass of everything that changed in their system, and also the effect of those changes. So, for example, in Komodor, you can see your service is unhealthy, you can see the last deployment that happened in your system, but also to see Sentry issues that arose or changes that happened in LaunchDarkly, or your own configuration management. So, Komodor tracks all of those different data points into a single very nice to use the platform and allows our users to troubleshoot efficiently.
So, we use feature flags not only as integration for our platform but also internally. And we believe that, like one of our strengths, is to give value to users as fast as possible. And feature flags allow us to open new features, new capabilities to a subset of customers before doing like a full-blown product. And this allows us to develop faster ‘cause we have a very specific customer in mind, or we open the feature flag only for us. And this in turn makes the feedback loop a lot faster. So, instead of opening a new feature for our customers and it will take months, we open it up only for a selected few, we test it with them, and this allows us to get feedback from real-life users a lot faster than we could without feature flags. So, we use both Sentry and LaunchDarkly for the feature flag part.
And today, I’m going to do an overview on Komodor, basically what is the platform. Then I’m going to show real-life use cases of one of our customers basically, that had an issue with one of his services, and he opened the feature flag that basically created a problem in the system. Then there was a Sentry exception, obviously, and it’s Sentry coded. And also, I’m going to show how you can use both Komodor and Sentry to troubleshoot the issues and to understand that the change arose due to a feature flag change, but it affected the whole system. Yeah. Did I miss anything, Dustin?
Dustin: No, that sounds great, Itiel. Looking forward to seeing all of that.
Udi: So, if you don’t have anything else you want to share about your use of feature flags, then we can get right to it and start with the show and tell. So, Itiel?
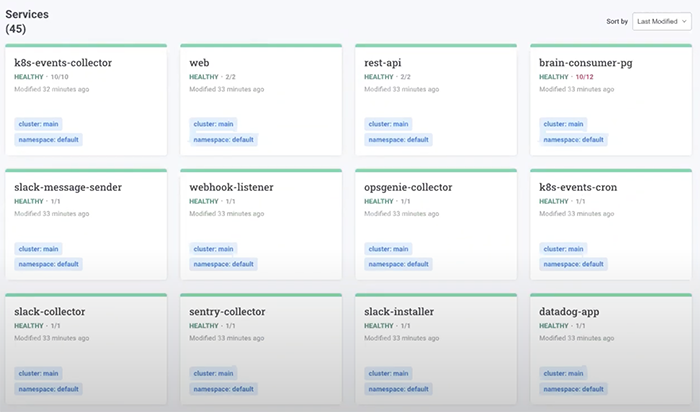
Itiel: Yeah, sure, sure. I’m going to start the show and then, one second, let me see if I share the screen. Okay. Hello, everyone. So, this is the Komodor platform we talked about a few minutes ago. This allows you to see everything that happened in your cluster. Basically, all of those like green tiles, they are all green ‘cause those services are healthy, they are services that are running on the production cluster on the main processor. We can filter the services by namespace, the DB use, the groups they’re using, and so on. Filtering and see like… web-related services. And also I can go and click on one of the services to see the complete history and complete timeline of the service and basically see everything that changed. And when I say changes, I mean both the infra side and the Kubernetes side. Between the old version and the new version. But more than that, I can also see the changes that happened from the Git perspective. So, I can see all of the changes that happened through the web application over the last 24 hours. So, this is like a full history of the service.

Now I’m going to jump into a different service, the REST API one that also has Sentry enabled. And it also has or had an issue with the healthiness of the service. So, I can see here in Komodor that I don’t only have deployments, but also health issues, Sentry exceptions, and LaunchDarkly feature flags that changed. So, here I can see there was a LaunchDarkly change, ‘save to DB’ that changed basically, yeah, one to zero changed the default variation from false to true. Comment: “very important”. Okay. It was an important change. I can see that right after the change. What happened is the service became unhealthy here. But before that, I got an exception from Sentry. So, in this use case, let’s press it again, what we saw is a series in Komodor that represents the REST API, a service that is running on top of the Kubernetes cluster. It had a LaunchDarkly feature flag change that changed something related to the database. And in turn, what happened is a Sentry problem and Kubernetes healthy issue. So, here, I’m going to jump over to the Sentry issue. And I think I’ll let Dustin maybe go over and do like a quick walkthrough over at the Sentry platform, and what you can learn from Sentry.
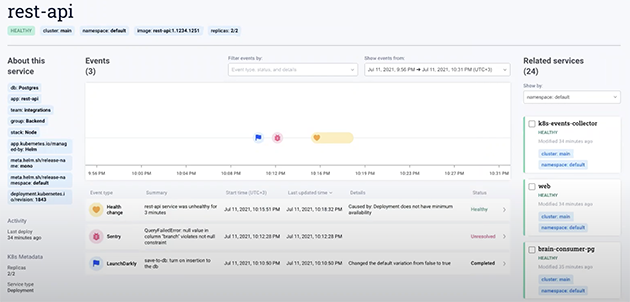
Dustin: Awesome. Thanks, Itiel. So, this is really cool, because what we just saw is, from the service level, we were linked via the integration directly into the contextual detail that Sentry collects around code-level issues that are specific to the Komodor project that we are just in. So, there’s a number of things that are linked automatically here contextually. So, first and foremost, we have tags. So, this is contextual detail that’s configurable and collected automatically from Sentry. So, you can see environmental tags there, handle tags, mechanism tags. This is where you’d also see feature flag tags if you set this up via the Sentry SDK. Another super helpful piece of contextual info is the stack trace here. So, in this case, you can see the exception value — the exception type and value, the stack trace here that appears to have crashed in non-app code. It’s right above there, Itiel, the JS tag in-app only. Yep. You can also expand that to look into it if you so choose. Yep. And you can get directly to the line of code which is correlated with the issue. Sentry is really focused on accelerating your decision-making here when it comes to being alerted to triaging and to resolving issues in real-time.
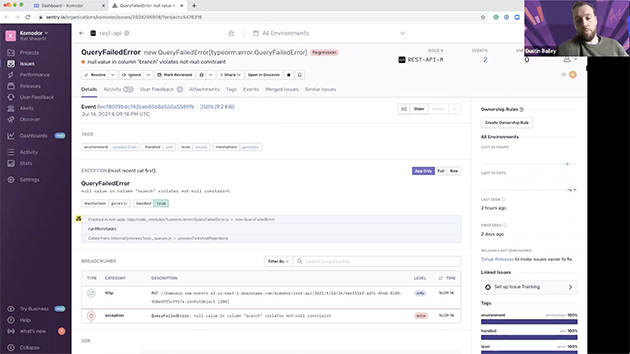
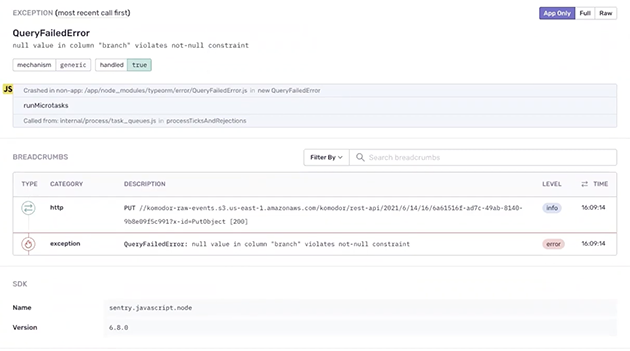
So, you also can accelerate decision-making on who this issue should be assigned to. So, we have issue ownership rules that you can set up based on file paths in the stack trace. Thanks, Itiel. So, you have options to do that. You also can associate commits with releases here. So, releases, you can get suspect commits. So, as Itiel showed commits at the service level, you can get detail on commits at the code level as well. Yep. So, we’re back in issue here. So, we’ve talked about accelerating decision-making when it comes to ownership, leveraging contextual detail to triage. I think the last — one of the final parts I want to talk about are breadcrumbs here, which also come as part of this issue context. So, this is the chronological series of events leading up to the actual exception in the code base. So, this is great in many cases for reproducibility. And these are going to vary depending on your SDK and your platform as to what gets collected here.
So, if you’re running on a — you might see DOM events if this is a front-end-based platform, you might see HTTP events and other types of database events. If this is a back-end platform, breadcrumbs can be super helpful for looking at events leading right up to when the actual exception occurred in the codebase. But this is all great because it effectively rolls all of this context into the observability layer at the Komodor level. So, you can jump directly from Komodor into this type of rich context at the Sentry level as well when you’re triaging these issues within deploy.
Itiel: Yeah, great. Do you want me to show something else, Dustin, on the Sentry platform?
Rahul: Well, I could speak to one thing. What’s great about this is when Komodor tells you there’s an issue and if it’s critical in Sentry through our ecosystem, you could also automatically create issues in whatever project management tool you’re using. So, your team will get notified — the right teams will get notified at the right time to fix the right problem. So, not only we’ll have the rich context, they’ll get the rich context in Sentry, the alert from Komodor, and have everything they need in the place that they work to go fix it. And that’s how we close the loop from like discover to seeing, solving, and then learning.
Itiel: Yeah. Can you show it, like open discover?
Rahul: If you want, you can open discover, and we can show you how to analyze your events over time. But the ecosystem that I just spoke to requires a little bit more integration.
Itiel: Sorry about that.
Rahul: No problem.
Itiel: Thank you, Rahul. And anything else we missed about the world or about the integration? Maybe I will speak for a second about adding the integration into Komodor. So, Komodor, in order to do so, we have an app in the Sentry marketplace but from like the Komodor side, what we need is to have the relevant environment variable enabled on the pod or like its label or annotation and Komodor basically understands that this is a Sentry project, we understand the name of the project and the environment variable, and then do the matching between the Kubernetes service and Sentry automatically. So, you don’t really need to work hard in order to make sure everything works. It works as expected as long as you use the default environment variable to configure Sentry. So, the integration is super easy, like two clicks away and you can have a full working integration between Sentry and Komodor. So, it’s very easy.
Udi: Why don’t you show us the integrations then, Itiel?
Itiel: Yeah, the integrations in here, I think it’s a little messy. But yeah, here we have integration. Sentry is already installed —
Udi: Naturally.
Itiel: Yeah. I can’t really show how to install it but you can also view the documentation I think on how to install Sentry. Yeah. This is how to install Sentry on Komodor from both sides, from the Komodor side and Sentry side. Okay. Anything else on the integration?
Udi: No. Sounds good, Itiel. Can you please share the link to the documentation in the chat for everyone to —
Itiel: Yeah, yeah. Sure. I am.
Udi: — to deep dive into Sentry integration?
Itiel: Yeah, I am sharing and we are also working on a new integration so it could be even better.
Udi: And I want to remind everyone that you can ask questions down below in the Q&A part and we’ll leave time at the end to answer them. So, don’t hesitate to ask anything that comes to mind. Okay, guys. So, let’s move on to talking about best practices. And I want you to share a bit from your customers or the experiences you’ve had yourself using feature flags. And there’s at least one big event that happened in recent months that we all know about. But let’s talk about the things from the Komodor and Sentry perspective and our customers.
Itiel: Yeah. I will say that from the Komodor perspective, what we usually see is like the first integration that our customers are doing with Kubernetes. And Kubernetes has a lot of interesting changes and events that affect your overall system health. But we do see from our customers that feature flags are like the ugly part of CI/CD, they are less monitored, they do cause a lot of issues. And by making sure that every time you open or close or change a feature flag, you can allow yourself to find issues a lot faster, basically, reduce the MTTR and allow you to stay in control even if you are using feature flags to move faster. So, I think the best practice is if you’re using Komodor to enable the integration between Komodor and feature flags. But even if you’re not using that, I think a very good practice is sending everything to some other tool just to know when feature flags are enabled or disabled so it won’t jumpstart when you have an issue, you had no deployment or no visible changes. And then you need to resolve to go into your feature flag platform in order to understand that change happened because someone somewhere in the organization changed something. So, I think this is the gist on my side. And Dustin?
Dustin: Yeah. I can say many of the sentry customers do utilize feature flags in addition to Sentry. Utilizing feature flags, I think it’s important to have a standardized process that’s well-documented and communicated for setting up feature flags and using them internally among teams to sort of coordinate and reduce confusion in that respect. I think when it comes to using Sentry — the feature flags conversation is definitely going on within Sentry across SDKs. I think the current best practice that exists within the Sentry tool for incorporating information around feature flags is the tag feature. I already kind of alluded to this at the beginning of the presentation. But again, just to refresh, tags are limited in size, they’re key-value pairs, and I believe the keys are limited to 32 characters, and the values are limited to, I believe, 200 characters. So, when it comes to being clear about which issues are linked to which flags, if you’re setting code level flags, you have the opportunity to also include that type of metadata within a Sentry tag that may be associated with the new feature.
We do have other options in the SDK for setting extra information if you need to provide a richer detail related to certain features in order to link that detail to issues. So, we provide that API as well through the SDK, where you can sort of set arbitrary information within an object related to a particular feature flag. So, I’d probably push folks to explore those two parts of the SDKs if they’re interested in incorporating their feature flag metadata into or associating it with Sentry issues. And also being able to get to the root causes faster when your team is implementing feature flags. If you don’t have the information within your platform, or the error rates within your platform for certain flags, Sentry can sort of give you that information; provide SDK-level API’s to get you to that information quicker. And these tags are also indexed, I want to mention that as well.
So, because they’re indexed within Sentry, they’re searchable within our discovery tool. We didn’t dive too deep into that in this demo, but you can also query across discover, and sort of look at the rates for issues containing certain tags for certain releases of your codebase. There’s a number of different ways that you can incorporate all the metadata that eventually becomes indexed within Sentry from Sentry issues, specifically within the conversation here related to feature flags, but in addition to many other applications when it comes to triage issues and sort of accelerating the evolution of your product, I guess is one thing that we’ve been talking about here, but also as part of that squashing issues as they arise. Or knowing that these features are healthy enough to deploy to perhaps a larger proportion of your users. Yeah.
Itiel: Good tips, Dustin. Good tips.
Udi: Anything else, Itiel? Maybe share a story that comes to mind from one of our customers yourself.
Itiel: Yeah. I think the thing that we showcase basically, one feature flag that crashes your application is something that we see for a lot of customers. And I think the more tricky part is a feature flag that doesn’t necessarily affect your service. Like it affects someone else in your system. And those kinds of issues are super hard to triage. I think tools such as Komodor and Sentry really help to pinpoint the relevant place to look at and to understand how to solve the issue and basically when to change it and why. But without that, I will say that a lot of the problems that we see are our customers that are using feature flags are a little bit blindfolded because they don’t really know when things change in your system. So yeah.
Udi: Anything — any others, and Dustin, Rahul, any interesting stories?
Dustin: I don’t have anything off the top of my head. Rahul, do you have any interesting stories that you’d care to share?
Rahul: Not of a customer, but there’s like an embarrassing one where we installed a feature flagging service on Sentry and slowed it down. I’m happy to share that blog post about how we used our own performance monitoring tool to try and fix the problem when we try to use feature flags.
Udi: Sounds good. All right. Do we have any questions from the audience? Anybody wants to ask anything before —
Rahul: Yeah, they do. We have three in the Q&A section.
Udi: All right. So, let’s start with number one. My feature flags usually impact several services at once, and every incident we have is becoming a game of cat and mouse. Which one is most problematic? What do you suggest to make this process easier to identify the problem? Coming from Victoria?
Itiel: Yeah, I think — Dustin, yeah. Go ahead, sir.
Dustin: Well, I was going to say Itiel the services timeline seems like a good candidate for an answer here. So, I don’t know if you want to speak to that within Komodor.
Itiel: Yeah. I think the service timeline, it indeed gives you like the fact that their feature flag changed, but also to see the issues that happen in a specific service. So, I think this is a great way. And the other way, Komodor very much like Sentry supports tags and annotations in order to do better cross-fitting between the feature of that, or to the service. So, you can also add your own custom tags. And I think you will show it both in Komodor and Sentry and this will give you a very easy way to pinpoint the affected service or the affected feature flag.
Dustin: Yeah. I agree. Just to sort of mirror some things Itiel said, I think you can leverage cross-project details in either platform. And as I mentioned, discover is a way for you to query across — all of the metadata across projects, so that cat and mouse can be — you can sort of, I don’t want to say — You can diminish the cat and mouse or shorten the time between chasing different things by having the ability to query across projects. And also to drill down within a project and get perhaps issue ownership or other ownership details related to issues to effectively communicate a little bit better or to even alert different project teams automatically for issues related to specific projects within Komodor or — Well, the project link between Komodor and Sentry so to speak.
Udi: All right. Next question is from Oren Mineo. Do you need to add the hooks for the feature flags to be identified by Komodor? Itiel, I think this one’s for you.
Itiel: Yes, yes. So, the integration is very much like the Komodor and Sentry integration, two clicks away and we integrate with LaunchDarkly and also like custom feature flag mechanism. So, all you need to do is to enable the feature flags and Komodor will automatically read the relevant metadata and tags from the feature flag configuration, and we will know how to do the cross-matching between the service and the feature flag.
Udi: All right. Next question is from Anonymous. How do I map Sentry issues to Komodor services?
Itiel: Yeah, so yeah — yeah, I already answered this when I talked about the Sentry integration, the remapping is between Sentry projects and Komodor services, so we know how to read the relevant environment tags and annotations that you have on top of your Kubernetes resource. And in this way, we know how to map between a Komodor service and the Sentry project. And this way, when you have an issue in your Sentry project, Komodor shows it on the service timeline.
Udi: All right. We have another question in the chat. Are there any best practices to use LaunchDarkly? I think this goes to every feature flag tool — Dustin, Itiel, do you have any suggestions for Nadav?
Itiel: Yeah, Dustin, go for it.
Dustin: I was going to say LaunchDarkly provides a lot of great documentation when it comes to the best practices for launching feature flags. But I feel like this is a very general question that can be specific to your team, your team’s philosophy on releasing feature flags, but I would recommend reading their documentation because I was actually in there recently. And I think it’s fairly descriptive on best practices and use cases for — not to put it on them, but I would say that they do a great job over there.
Udi: Okay. Next question is from Ben, an interesting question. What is Komodor versus Sentry in terms of its visibility to exceptions? Do they complete?
Itiel: Yeah. So, I think you can see that Komodor and Sentry work best together. We don’t compete. What Komodor shows is Sentry issues and also Kubernetes-related issues and that’s pretty much it. We don’t show exceptions, we don’t track exceptions, or have an SDK that is running on your application. So, Sentry is very much focused on the exceptions themselves, and Komodor is more on the high-level view of what is happening in the Kubernetes cluster and the service.
Dustin: Yeah, I’d have to agree with Itiel. The integration effectively rolls all that detail into the observability stack of the system level. So, it’s a great way to be able to leverage the context, the unique context that each service provider or platform provides for debugging complex issues related to deploys there.
Udi: I also think we work best together. And another question from Victoria. Do the events Komodor receives from Sentry are just displayed with no context, or what more information do you show?
Itiel: Yes. So, we show all of the relevant metadata that Sentry has, like the important piece of data which Sentry has. And other than that, we do like to encourage our users to go into Sentry to do a deep dive on the breadcrumbs and stack trace itself. Because I think it’s something that has like a very good UI. So, we give like the assignee, the level, the project, a couple of more things in terms of like metadata. And in order to deep dive, we just give a link to the relevant annotation.
Udi: All right. Another anonymous question. How can I set up Komodor for my company?
Itiel: Yeah. So, we have a free trial. So, like check us out, very easy to install and you’re basically like two clicks away from getting Komodor. Yeah, I see you posted it in the chat,
Udi: Yeah, this is our website in the chat. You can just go there and click on the free trial button. In case you missed it, Rahul shared the story of our Sentry implemented feature flags and accidentally slowed down the services just up there in the chat. So, check it out as well. Let’s see what we — Oren is asking another question. Can these services integrate into our MOM?
Itiel: I’m also not sure. MOM?
Udi: MOM.
Dustin: Is that message-oriented middleware? I’m not sure what MOM might be.
Udi: Oren, can you elaborate in the chat, please? In the meantime, there’s another question. Will both Sentry and Komodor alert on the same issues? How do they differ in terms of the level of penetration into our stack? That’s a really good question.
Itiel: Yeah, I think I already covered this in the comparison. Sentry focuses more on the application level. We had an exception, this is the stack trace, those are the environment variables and so on. Komodor, we focus on you have an issue in your cluster, in your service, in a couple of services, so it will give you more of like a Kubernetes view of the service or of the service level view, while Sentry bring you more of like the application view.
Udi: All right. Dustin, do you have anything to add to that?
Dustin: I think the only thing I’ll add is that you have control over alerts you received from Sentry so you can — we follow the path from Komodor via the integration into Sentry. And so you have the option to choose what part of your workflow you want to incorporate in addition to that. So, if you wanted to follow that initially from Komodor into the issue, and then assign some folks on your team the issue, you have the option to set different alerting options. So, if it’s a PagerDuty, or Microsoft Teams or Slack, you have the flexibility to sort of maintaining the integration as we showed it, or to add additional alerts as necessary.
Udi: All right. Oren, who is it, what about the MOM? Is it mom? Otherwise, we can’t answer the question. All right.
Dustin: Have yet to tell my mom about Sentry.
Udi: Does your mom integrate with Komodor?
Dustin: Well, I don’t know. I’ll have to ask her.
Udi: We’ll talk about that offline. Any more questions from the audience?
Itiel: No, it doesn’t seem so.
Udi: No more questions. Okay. So, let’s wrap this up, guys. Any last words before we go?
Itiel: No. I think if you are using Sentry, you should use Komodor, and if you’re using Komodor check out Sentry. And I think the integration between both of these tools can give her like the users full visibility on what is happening in the system on all different layers of the stack. So, it’s great. Dustin?
Dustin: Yeah. I feel like anything I say is going to reinforce kind of what you just said. I think the timeline within Komodor is very cool. Being able to look at multiple services overlaid and to be able to track all of the issues and how those issues ripple through different services and also the integration with Sentry being able to effectively roll, develop a level context into the observability layer. I think both those things combined are a great approach to managing the complexity of a growing distributed system. So, I think that’s probably how I’ll sum it up myself, but I’ll kick it over to Rahul in case he has anything else Sentry or Komodor related he wants to finish up with.
Rahul: It’s always hard to follow Dustin because he does such a great job capturing it. I just wanted to echo what Itiel said, we also have a free product. You can try both of our tools absolutely free. All of our integrations are free for 14 days. So, you can set up Komodor and Sentry. And we’re always accessible on Twitter as well. So, if you have any other questions after here, you can reach me at [email protected] or you can reach us at Twitter @GetSentry.
Udi: All right. So, let’s wrap this up. It’s the same for Komodor, follow us on social media on Twitter and glad to have this event. It was short and sweet and very interesting. So thanks, everyone. I’m Udi and we’ll see you next time. Have a good day or night wherever you are in the world.
Itiel: Bye, everybody.
Udi: Bye.