- Home
- Resource library
- Webinars
- Troubleshooting Permissions in Cloud-Native Products w/ Authorizon
Troubleshooting Permissions in Cloud-Native Products w/ Authorizon

Mickael Alliel
DevOps Engineer @Komodor

Or Weis
Co-founding CEO, @Authorizon
You can also view the full presentation deck here.
Or: It’s a pleasure to be here. So, Mickael, we’re gonna talk today about a combination of permissions, authorization, and troubleshooting in cloud-native applications.
Mickael: Yeah.
Or: It’s a very actually interesting intersection. Yeah, so if we kind of dive in, the first thing that comes to my mind thinking about it is just being in the Cloud-Native space. What challenges does that bring to the table as we’re thinking about permissions and building apps?
Mickael: First of all, I think it brings so many challenges and all kinds of perspectives. In authorization specifically, it makes it really hard to understand what’s happening, when, and who did what?

Or: Mm-hmm.Mickael: That’s exactly what we’re gonna talk about, along with some best practices on how to mitigate the effects of these issues.
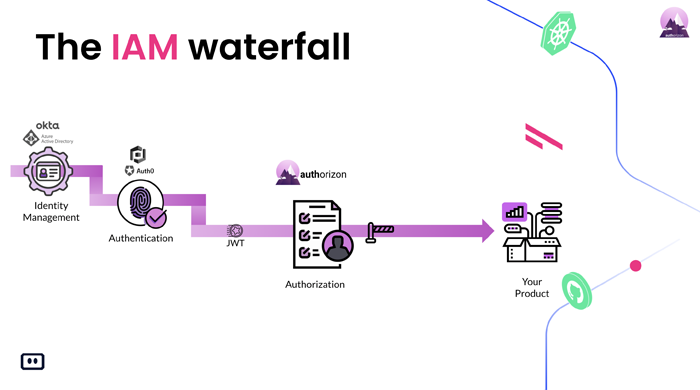
Or: Right, right. Yeah, so we’ll be talking a lot about the characteristics of Cloud Native apps and how you address them. But first, maybe we should – before you start talking about permissions, maybe we should kind of cover the basics of what it actually means when we say permissions. So, permissions or access control or authorization is part of a larger space called IAM (Identity Access Management). Sorry. It starts in identity management. So, things like Octa, Azure Active Directory, where you manage the identities on the organization side and from the app builder perspective, the customer side. And then you move to authentication. Things like Auth0, Cognito on AWS, and other solutions like that where you focus on identifying who’s at the door and deciding if you’re letting them in. And then you finally arrive at the third step which is the most complex one authorization or access control. As we said before. Where after you’ve had authentication identify who’s at the door and let them in.
Mickael: What can they do?
Or: What can they do now when they’re within the house? Can they sleep in your bed? Can they eat in your kitchen? Can they set your room on fire? Please don’t set this place on fire.
Mickael: I’ll manage. But correct me if I’m wrong, it’s not only from the user side. It might be also machines. Any, anything that can connect to a system and that is some kind of identity to manage and authorize to do something.
Or: Exactly. So, it’s both the human actors but more and more it’s becoming more automated actors. Its automated agents are part of the solution we’re building. You can think about the microservices that you have within your infrastructure in Kubernetes.
Mickael: Talking to one another, maybe CI/CD some kind of information.
Or: Right. Can be third-party services that you’re integrating with, coming in with webhooks and stuff like that. It can also be automated agents acting on behalf of your customers. More and more, applications are acting within applications for our users. So, think about things like Zapier and if and stuff like that where and machine learning agents, in general, are becoming critical parts of applications and how users are using applications. Also, when we talk about users or with an application, we should probably differentiate between the kind of different stakeholders. So, we have both internal and external stakeholders.
Mickael: Internal can be developers, operation teams, security, product, compliance, and sales. And external maybe your customers or tenants or accounts. However, you can define it in your organization, a third-party system that you just talk about.
Or: Exactly.
Mickael: Even partners that you can connect to your system.
Or: Yeah. Auditors, so you have third-party players that are coming in to connect to your system just to check that the checks and balances that you have in place are the right ones.
Mickael: So, you need to authorize somebody to check your authorizations.
Or: Yeah, exactly. When I think of this the first thing that comes to mind like the bell that rings is that, this combination of things is super complex. It affects our entire infrastructure. It affects our entire application level. It affects our organization like the developers working on this. The people we work with are obviously our own customers.
Mickael: Yeah.
Or: So, getting this right or getting this wrong can have huge impacts on the quality of the product that we’re trying to deliver. And with that, there’s nowadays, a significant and dramatic change in how we think about building cloud-native applications with authorization.
Mickael: So, we have to do it like 5 or 10 years ago. Before Kubernetes and the cloud-native boom.
Or: Terrific question. So, 5 or 10 years ago, what you had is nothing. So, you had people just coupling together things on their own, just dropping code in and hoping to have a working solution and then, implementing everything from scratch. Also, you had them doing everything proprietary. You had a couple of gems like if you use a monolith solution like, I don’t know like Java, you’d have something in Spring framework. So, the Spring framework would provide.
Mickael: Managing the authorization.
Or: Right. So, yeah, you get something built but that doesn’t work anymore for microservices. You’ve got everything kind of spread out for you. So, nowadays, it was hard from the beginning to build everything on your own and nowadays, it’s insane.
Mickael: Even if you were using the spring framework which manages the authorization for you, it’s only happening in that specific service.
Or: Right.
Mickael: And to be honest, you want something to be managed from the outside, managing everything from the tablet.
Or: Exactly. So, especially when you go into microservices, if you try the same approach, meaning you take the same code and you replicate it for each microservice like as if it was you, to support the same model with. What would happen is that they’ll start to drift away from one another and you give it like 3 months and then you’ll have chaos.
Mickael: Yeah.
Or: So, that’s how things used to be and why they kind of don’t work anymore. And nowadays, luckily, we’re starting to see a new trend. There are new best practices which we’ll touch on in a minute and also new solutions. Things like OPA, (Open Policy Agent). One of the leading examples. So, OPA is essentially an engine that you can use to build a microservice for authorization. You load data and you load rules into it in a specific domain, specific language. And that can become your microservice or authorization and it can scale out with your cloud-native application. So, that’s kind of the difference between what we used to have and what we have today.
There’re also things like Google Zanzibar and other open source solutions. Another one that I like obviously is Opal, our own extension of OPA but we’ll talk more about that in a minute. Yeah.
Udi: Can you talk more about what makes cloud-native apps so difficult? What are the inherent challenges? Yeah.
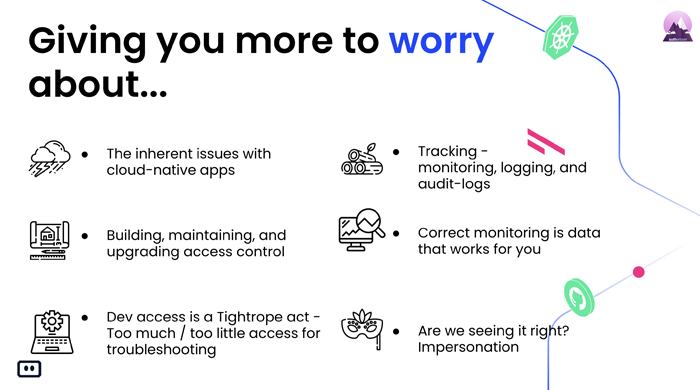
Mickael: So, I’ll be happy to touch a bit about that. Cloud-native brings all kinds of issues into your production systems and applications mostly being one being distributed. This means that you have a lot of different services, doing multiple things that might be connected one to another, talking one to another. And this being a fact, it makes it that you have a lot more changes coming in into your system application. Everything, you are kind of changing a bit, your way of walking to be more agile and making a lot more changes.
Or: Updates or like it becomes more dynamic. You have like CI/CD. Everything is changing all the time. It’s not like one component. You deploy it like once a month. Everything is constantly moving.
Mickael: And let’s take for example like you have a customer with complaints that is trying to access a menu in your application and you cannot access it. Where do you start troubleshooting that issue? What kind of permission does it have? Where does the develoepr start from? What service do they require to start from, who did he talk to, what kind of the, the whole waterfall of actions that happened up to that point?
Or: Yeah, with microservices and especially with Kubernetes the elements as part of the decision plan of who has access to what? There are a lot of enforcement points, a lot of different points where that access can fail. And when it fails, it’s really hard to know at which point did it fail. So, having the ability to understand and build your troubleshooting and build your authorization at the get-go to face is super important, because otherwise you can get lost really quickly.
Mickael: Definitely. I think there’s a lot of stuff that you can do to mitigate the issues later on. Some kind of best practices or a way to build your system and applications in a way that’s easier to manage and troubleshoots along the way.
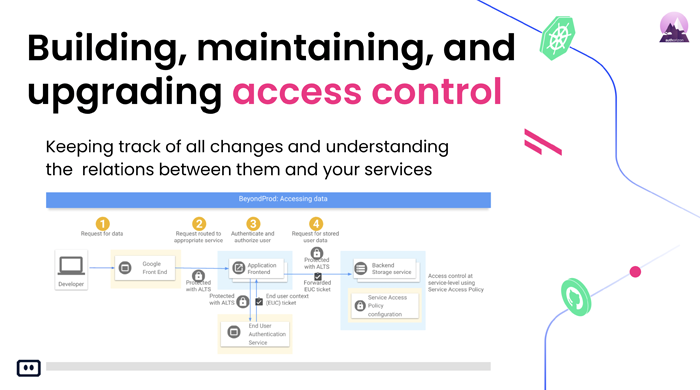
Or: Yeah. And also, it adds the access control aspect adds a new playing for the application to your building. So, the aspect of building, maintaining and upgrading where its control becomes more difficult. Because now you have a separate layer, that separate microservice or authorization for example and you need to manage that on itself. You need to understand the different relations that you have. You need to start understanding what models are you working with. Are you working with RBAC, role-based access control? Are you working with attribute-based access control? And all those different things will change the way your system behaves.
So, for example, let’s say you’re using attribute-based access control. And you assign the attribute that only people logging in from Minnesota should have access to. So now, when your developers are accessing the system, they get different attributes if they’re not from Minnesota.
Mickael: Exactly.
Or: So, they will lose the ability of understanding what’s going on. If they don’t have the whole picture of how the solution is built with authorization.
Mickael: But not even the user, even the one who’s managing, the application, we have trouble understanding why it’s happening.
Or: Right.
Mickael: Like the more fine-grained control that you want to have in your access control. The more issues you’re gonna have troubleshooting, when somebody’s competing.
Or: Right. So, it essentially becomes a point where developer access is essentially a tight-rope act. You’re trying to balance it. So, you obviously don’t want people to have access to things that they shouldn’t have access. That’s the basic concept that you want with authorization, right.
Mickael: Yeah.
Or: But what happens when things escalate? When there’s, it’s 2 o’clock in the morning, things are not working, you’ve got paid your duty springing up your developers to handle the problem, and they don’t have the right access to work on the solution. Or even worse, they don’t have the right access to see what is the problem that your customer is experiencing.
Mickael: Well, let’s be honest, another year, it’s happened to me a lot of times.
Or: How many times?
Mickael: Oh, well, at least 30.
Or: Okay. It makes sense. So, that’s one part. You’re limiting the access so you want it to be tight, but on the other hand, you want to enable your developers. But also, your salespeople, your support people to be able to work with the system with the right access, with the right ability to see what’s going on. And if you don’t have that, well, that just means you’re gonna suffer.
Mickael: At the end of the day, when somebody’s gonna wake up at 2 AM to try to suffer anyway. They’re gonna suffer anyway. In this way, you’re gonna suffer too because you’re gonna have to answer the call and help them get the access they need to have.
Or: Right, right, right. So, this becomes a significant challenge and also, the data that you need now is becoming more advanced, maybe you wanna talk a bit about it?
Mickael: Of course, yeah. So, when you’re talking about troubleshooting, you’re talking about information. What information can you get in a relatively short-time span to troubleshoot the issue as fast as you can to make your customers as happy as you can. And it starts from building your application right. Having the right metadata or information on your services, on your cluster, on your even logs or on the clouds. It can be, you know, it depends bit on how your organization is built, if you’re working with users, specific users, or with accounts or of your access control based, if it’s the role of permission or attribute-based. And it makes it, a bit harder to troubleshoot if you don’t have all that data from the get-go organized and you need to get as fast as you can to understand what is the issue, where it happened when it happened.
Or: Yeah.
Mickael: And if you have all that information, it becomes a lot easier.
Or: Yeah and it’s also important to understand that with authorization, the data plan that you need to work with is really expanded. Just think about all the things you need to connect as part of an authorization process for an application. Let’s say you want something simple, like only users that have paid for a feature, should have access to that. So, that data, that doesn’t sit in your database. That now sits in a third-party solution like Stripe or Rapid or Chartify.
Mickael: They need access to know it’s somebody.
Or: Yeah, so you need that to be synced with your application. You need that to be synced with your authorization there and you need that to be synced with your monitoring, auditing, and logging tools. Because otherwise, you’ll have gaps in your information. And if you don’t plan for that in advance, the chances of getting that right are essentially zero.
Mickael: Zero. I think the biggest gap that you happens when you work with third-party services is that every time you have a hope in your data and something that’s happening. The data is changing a little bit. And a third-party service might refer to your user with a specific ID when it gets to your system. It’s gonna have the email ID. When it gets to another service is gonna have another ID. How do you keep track of all that?
Or: Yeah. So, you need to keep track of that just to get authorization, right. So, you don’t have gaps so you don’t by mistake give people access that they shouldn’t have or also a bad thing not being able to give them access but as you say, it’s also important to be able to have a unified picture.
Mickael: Yeah.
Or: So, when you come to troubleshoot things, you can speak a unified language.
Mickael: Exactly.
Or: Otherwise, it’s like the tower of Babylon and everything just falls apart very quickly. So, I think what we’re already beginning to see is that planning here and building things right from the get-go is super critical.
Mickael: Not to say that you cannot, you know if you’re already going in a company for 2 years and you have an authentication system already said, you can change and make it better.
Or: Of course. Also, I never encourage people to like just throw everything out the window and start some scratch that’s a bad idea.
Mickael: You can do it gradually. It takes time.
Or: Yeah, especially if you have something working, that’s great. But a lot of times you discover that you need to add more things and as you’re adopting new technologies, adopting greater scale, you end up having to change. And when you do those changes, it’s important to keep in mind the challenges and also the best practices that one can apply to not fall into the pitfalls that we’re kind of mentioning here.
Mickael: And also, that this change, this is the exact point something could fail. Which is kind of scary.
Or: Yeah, it’s super scary. So also, it’s people shouldn’t, probably shouldn’t go about changing their entire authorization infrastructure in one day. It should be a gradual process and they should do it with clear goals in mind.
Mickael: Yeah.
Or: Go from the like the feature that you want to implement, identify the capabilities that you want and then gradually upgrade. Another example here that comes to mind here and things that people often don’t think about that they’ll need to do and kind of touches on the troubleshooting aspect as well is impersonation.
Mickael: What happens when an issue gets in contact with a customer and you cannot understand what happens to it.
Or: Yeah. So, the customer through your authorization, they’re they have a lens, they have a filter where they’ve seen the system in a specific way. That is unique to their tenant and unique to their user, unique to their system. And now when you’re logging into the system as a developer.
Mickael: Everything works right. It’s like magic.
Or: Yeah, it looks great for you, but it’s not the same for them. And that can be both for like bugs but also users Experience issues. So, impersonation is a feature that can be critical and getting it implemented. So, maybe I should clarify. So, impersonation is the ability to see the system through the eyes of another user. Not to become another user or log in as another user because that’s a vulnerability. That’s a security issue.
Mickael: It’s like sometimes when you contact the support of some kind of service and they ask you, give me permission to become you for one second, just to see what you’re experiencing.
Or: Exactly, exactly. So, when you do that, you don’t give them your password because that would be a big no security-wise, right. But you do have something built into the system that enables that context, you that view ads option if you wanna maybe talk like Facebook. And that could be critical both for your support and professional services and definitely for resolving bugs and issues in the system itself. So, I think we kind of painted a very gloomy, very painful picture here that I guess if you don’t invest time and effort and think about it when you build authorization nowadays for cognitive applications, you’ll essentially be f**** Pardon my French.
So, what can we give your, our, audience as kind of tips or best practices so they won’t be too afraid so they will and when they decide to do this, eventually and they will. What can they do to get this right?
Mickael: Awesome. So, there’s a lot of things that you can do to make your life a lot easier when troubleshooting and understanding your system. Keep in mind that you don’t have to do everything to actually for it to be useful.
Or: Right.
Mickael: You can start with something, so it helps you and iterate on the process and understand what exactly your system needs to travel through deficiently. First of all, let’s start with the information that you might need. If we speak from the Kubernetes or the distributed cloud-native system that we have nowadays, that rotation, labels that are properly handled, let’s say, or that you’re having your logs even, that everything is connected together in kind of a unified language. Makes it a lot easier to understand what’s happening. It might be a service name, a cluster name, what account is currently doing an action in your service.
Or: So, have that connected into your like annotations and Kubernetes.
Mickael: Yes, yes. Have everything labeled properly. If you have a deployment of a database, it needs to have what version it is, what’s the name of the database, which kind of environment it is on. Maybe which user has done a certain query so you can understand exactly who has done that.
Or: So, context, annotations, maybe connect this with your tracing.
Mickael: If you have tracing, that’s even better. Tracing gets a lot harder to maintain when you have a lot of code but it’s one of the most important part of monitoring and troubleshooting, I think.
Or: Right.
Mickael: Would you like to enlighten us a bit about policies and authorization that we got?
Or: Yeah, definitely. So, there are a lot of nowadays with the new technologies and open sources coming up, there are a lot of best practices that if you stick to them, will solve a major percentage of the problems before even you get to troubleshooting. And when you get to troubleshooting, we’ll make it easier for you. I think the most important one with the one which also was kind of championed by OPA by Open Policy Agent which is a CNCF graduated project is decoupling policy and code.
Mickael: Can we start a bit with what is OPA? Like in a few sentences?
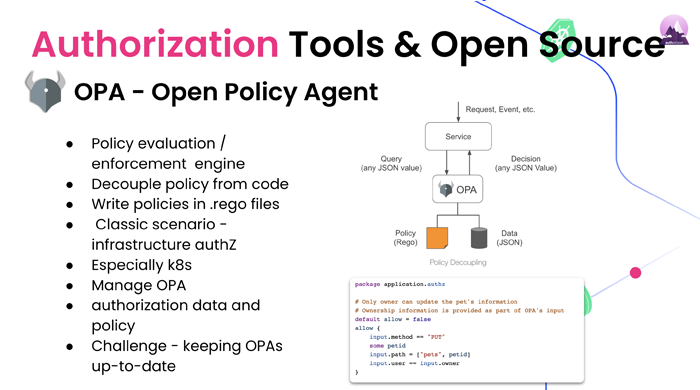
Or: Yeah. So, OPA or Open Policy Agent is essentially an agent or microservice written in Go that you can use to create a microservice for authorization in your system. You load data into it. Json documents that describe your world picture for authorization. For example, your list of users, their roles, attributes about them. Which departments do they belong to? The different services that he might have and you load code into it in a domain-specific language called Rego. And that as it becomes part of OPA, you can then come to it and ask it queries. You can say, ‘This user is now trying to access this file’.
Mickael: Can they do that?
Or: Can they do that? And OPA will tell you, yes, no, or give you.
Mickael: Is there a maybe or?
Or: So, it can give you, it can return data. So, it can say, it can give you, for example-.
Mickael: A file shell access.
Or: Yes, so it will, for example, you can use it to create a subset query. It will give you a query that you can use against the database. Filter that will only return relevant data that that user can see or you can query the database and then ask OPA to filter the data. So, it will clean out sensitive information for example. So, there are multiple ways to use OPA. At the end of the day, it’s an engine running code. By the way, if you’re familiar with Pro-log or Data-log, it’s based on those kinds of technologies. So, not only understandable but by the way, there are also other solutions that you can implement a microservice for authorization, things like also or Google Zanzibar implementations like ORY, that’s ORY. But the main player today is really OPA.
So, you end up creating a microservice for authorization and the main thing you wanna do there is decouple your policy and code. So, you want all the code that handles authorization to be exclusive to your microservice for authorization to OPA in one example. That way you don’t have that code replicated across multiple microservices.
Mickael: Which is deployed once and everybody communicates with it.
Or: Yes. Also, you can use that once you work that way, you can apply GitOps. You can have a specific way where you hold your policy as code in a repository and you go through tests and checks and then you can gradually deploy it into your microservice for authorization. If you do it otherwise, you’d end up having to shove code into different microservices and you have them coupled. So, every time you change a different part of the application or change the authorization then we have to change everything. And that will obviously be very painful. So, decoupling policy code is probably one of the most important best practices that one can implement when you’re doing cloud-native permissions for your product.
Mickael: Another thing that, when you walk with authorization, you sometimes want to update things on the fly. Because what happens if you need to omit access from some user right this moment. You don’t want to spend the time with the CI and the test and deployment and waiting for your code to become available in production, you want it to happen now.
Or: Spot on.
Mickael: The problem with that is when things happen on the fly kind of live without any kind of let’s say audits, it becomes a lot harder to understand what changed exactly. How do you keep track of these changes?
Or: So, your attention on two things. One is the importance of having things work in real-time.
Mickael: Mm-hmm.
Or: And especially if you’re working in the application layer and adding the infrastructure layer that becomes critical because users want to change things on the fly.
Mickael: Yeah.
Or: So, first of all you need when you’re building authorization as you pointed out. You need to be able to plan for real-time. Otherwise if you try to add that data it’d be problematic. So, you need to keep as if that is the best practice. Think real-time for authorization from the beginning and then, you want to have a system that enables you to have kind of transparency or ability to see what’s changing. You want the ability to listen into the events that are propagating through your authorization system. So, you want to connect.
Mickael: Dashboard backup is what you can manage and see what’s happening.
Or: Yeah, you want two things. One, a way to control how you push in new policies is a new data. So that can work with GitOps. So, a lot of people think oh if I’m working with GitOps that means that it changes only when I deploy things.
Mickael: Not always true
Or: That’s not always true exactly. So, you can have a GitOps channel that translates into a real-time channel. So, you push into Git and you have something listening there and pushing that in as real-time updates into the system in life. But you still enjoy the GitOps pipeline. And obviously, you want something that kind of enables you to manage it though. So, you look that will be like a back office or an audit log interface.
Mickael: But now I’m beginning to think people that can change the authorization live right now.
Or: Right.
Mickael: How do you manage them then? How do you manage who can change the authorization?
Or: So, it becomes a cursive. So, you have authorization for your authorization?
Mickael: But who becomes the like big administrator of everything?
Or: Yeah. So, that’s a decision that you need to kind of make early. You need to decide how you implement the authorization for your authorization. The basic way to do it is to do it in a different level. So, you have the authorization running in the application level and you have authorization in the infrastructure level enforcing access. So, for example.
Mickael: Kind of a really small subset of people that you can trust.
Or: A subset of people or a subset of rule or systems that you can go through. So, for example you can say you can only change the authorization through Git. You can only change the system through a specific interface.
Mickael: Which has its own enforcements of like code reviews and checks.
Or: Exactly. So, you wanna have a pipeline that controls how you do changes. So that kind of connects to the GitOps approach or policy as a code approach that we mentioned before.
Mickael: Which is kind of nice, because if you do GitOps its kind of also give you a history of what’s happened and who exactly push the change.
Or: Right. So, to recap on that so we want to decouple policy and code. Enable them to be updated in real time. And when you do those updates, you want to be able to control them through a policy as code or a GitOps procedure. Then what you kind of already hinted on is what we provide to the other people in the organization, the back office or interfaces.
Mickael: Which is not so necessary as much information as possible but the quality of information
Or: Right. It’s the quality of information. It’s also the right interface for the right person.
Mickael: Yeah.
Or: So, a developer would want one sort of interface. A DevOps engineer would want a different interface. A security person, different interface.
Mickael: On reports.
Or: Reports or dashboard. Have it feed as audit logs or logs into their sim. A product manager, we want the different interface. So, we already kind of listed the fact that we have a lot of stakeholders. So, we want to build that system that GitOps layer. We want to enable connect different interfaces on top of it. So, each user, we can provide the right experience for them. So, everyone would be happy. And if we take that as a best practice, think about, we’re going to build a back office. We’re going to build interfaces for the different people. It doesn’t mean that you have to build them all at day one. Yeah. But you want to think about building -.
Mickael: The people.
Or: Yes. So, that’s one of our best practice. So, we decouple policy from code. We enable changes in real-time. We do those changes through a GitOps channel and we provide interfaces on top for the different personas. And to wrap it all up and connect it with what you mentioned before, those processes will all have troubleshooting built into them. So, we have logs, we have audit logs, we have annotations, baked into all of those processes. So, if we trigger something from a product manager interface, it will trickle down for all through the systems and we’ll be able to see that that’s what happened.
Mickael: Which might think when you’re building an application or a system, what do you need to troubleshoot issues.
Or: Right. So, it’s really important to keep that in mind. So, when you’re building those interfaces, you need to think, oh, this will now go from this interface into our GitOps and that will then go to this microservice that will then talk to our third-party system like Stripe. So, you wanna paint those pictures and think about how you annotate that process.
Mickael: Exactly.
Or: So, when you go back to troubleshooting it, you’ll have the ability to generate the right data to give you the right answer. So, you’ll know which interface to use. So, you’ll know which users were affected. So, you’ll know if you need to apply impersonation. So, you’ll know if you need to go to a different source to look at where the problem is. Otherwise, again, it will get chaotic as we mentioned beforehand.
Mickael: But even if you have everything perfectly laid out in terms of information and access and you’ve thought about troubleshooting in mind before building a system. The moment you have 10 different things that you need to go through when troubleshooting, it makes it almost impossible to understand and connect everything that happened together.
Or: Right. So, like I wonder if like do you have tips for how we can go from connecting GitOps to our data collection or have like a tool where we can view the data in a way that is tailored for each situation.
Mickael: Yeah. So, I think the right answer for that is to have a tool that can unify all your information in one place and connect what’s happening and in like a timeline of what happened exactly in your system at that point in time. That’s exactly what we do at Komodor, which we’ll talk about in a bit. But as you know 10 years ago people used to do it also it just was bit more difficult.
Or: Right. So, I think Komodor obviously is a great way to approach it but I think in general the mindset that you have in Komodor is collected information that is relevant and presented in a unified way somewhere.
Mickael: Exactly. Some kind of centralized.
Or: Yeah. So, maybe people won’t be able to build a great product as Komodor to do it. But even if you just cobble something together, even if you just have a database or a logging solution where you feed data into there, you’ll be in a better situation.
Mickael: For sure.
Or: And if you’re building complex authorization systems, you’ll probably need to get into that example.
Mickael: Yeah.
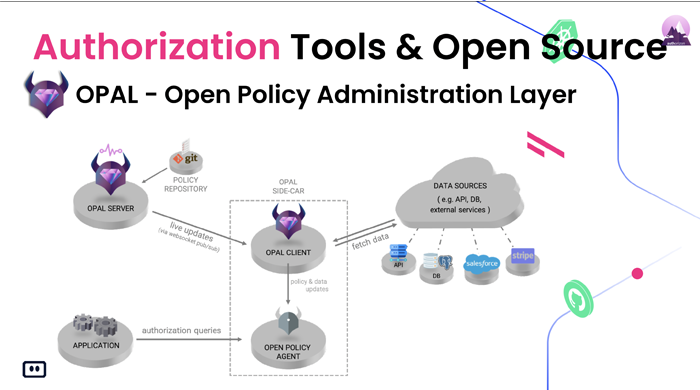
Or: So, it’s also good to kind of plan for that in advance. So, we kind of mentioned the real-time aspect of updates and there, I feel kind of obligated to mention Opal. So, Opal is an open-source project that I’m one of its maintainers. OPAL stands for Open Policy Administration Layer. It’s obviously a plane for OPA, but that’s because it’s meant to work with OPA which we mentioned before.
Mickael: Which is a requirement for it?
Or: It’s not, so yeah currently it only works with OPA. Maybe in the future we’ll have it work with other solutions but currently, it’s focused on OPA. OPA today doesn’t really have the ability of being updated in real-time. The best it offers is a polling solution. You can tell it. You poll this server to get new updates for your pods but that’s not real-time and that is often problematic with the application there because as we’ve said before, things change in real-time. And a user now invites another user who wants that to be applied now. You need emergency access. The developer needs now to be able to see the system from the eyes of-.
Mickael: But if you’re thinking it’s not in pull for that access. If you pull every one second, three seconds. Isn’t that enough?
Or: So, it depends on what you’re building. So, first of all, if you pull that frequently, you might start facing performance issues. And also, you won’t be able to apply it to different parts of your stack differently.
Mickael: Right.
Or: So, think about, it’s no longer just one microservice that requires authorization. You have a sidecar. Ideally, with the way you work with Opal, you have a sidecar, pair of microservices performing the authorization layer for it. So, now, if you have a lot of microservices constantly pulling your server, it will cause a lot of cost, a lot of friction. And you need to, so you either slow it down or you pay a lot. Obviously, a better option.
Mickael: Struggle to balance.
Or: Right, right. So, ideally, you can avoid that with just having your updates in real-time. So, that’s where Opal comes in. Opal sets us alongside OPA, subscribes to a pop-up channel that’s provided by Opal server and then it can receive updates on changes according to topics. So, each microservice can say, ‘Hey, I’m responsible for topic A or topic B’. For example, I’m a microservice that works with billing. And then it subscribes to that topic and when the billing information changes, the authorization data for that changes, only then will be updated. And when it’s updated, it will be in real-time. Another thing that Opal provides is the ability to aggregate data from multiple sources.
So, you can tell it’s a change now happened at Stripe and then you can teach it through a simple Python module to go and collect data directly from Stripe. And that’s in that way you both solve the real-time aspect and the distributed data plan aspect.
Mickael: We also provide some kind of, you call it administration layer. You kind of admin area to manage all these policies and real-time updates.
Or: So, we provide the ability to connect the policies to your OPA through Opal through Git Repositors.
Mickael: Okay.
Or: So, with Opal by default, you erect usually a web server that it will poll or you can do it on an S3 bucket or something like that. With Opal instead, you can work with GitOps. So, you load your data into a Git repository and then when you wanna change things, you just push them into Git. And that will trigger a webhook into Opal that will propagate everything else across the different microservices. And you can have again, each microservice subscribed to only different subsets of that Git repository. Yeah. Different policies within that git repository. Yeah, so it both, it distributes your policies through Gits and provides GitOps for it and also the data page, as I mentioned before. Yeah. So, Opal is open to, oh but what it doesn’t do, it doesn’t do like testing and it doesn’t do like a playground that you can work on managing the policy itself and offer the policy itself. That’s something you’ll find more on the OPA side with a service that the company called Styrax. Styrax is a company that built OPA. So, they have a solution called Styradas, which provides all those capabilities to how you manage and write policies and build them across the organization in a more managed way. So, Opal only does the administration aspect of delivering the policies that you’ve written.
Mickael: Actually, reinventing the wheel and inventing a new policy language and all of that
Or: Yeah. Another thing that Opal doesn’t do is the interfaces themselves. It only provides the updated player. And the interface itself and all the management components like a user management screen and an audited log and the impersonation and emergency access, all of that. That’s something that we provide as part of authorizing. As a sales service which will be available in as self-service.
Mickael: Awesome. Is it available already today?
Or: So, everyone can subscribe on our website today and it’s already working. We’ve got the customers in production but it’s not open to the entire public. So, you can sign up today and we’re addressing people according to the order that they signed up and give them gradual access into our early access.
Mickael: It sounds good.
Or: It’s one way to go around deciding who can do what and authorization is all about making decisions. And so, we in this aspect, we try to keep it simple.
Mickael: That’s true.
Or: Yeah.
Mickael: So, from there I wanna jump a bit about troubleshooting and how you used to troubleshoot 5 years ago when everything was a bit simpler. Imagine that you have an alert popping up, let’s say in the middle of the day, so your slack has a pager duty alert, and it tells you that there’s high latency in some kind of service in your system.
Or: Right.

Mickael: What you usually do is first of all, open the alert, try to understand where it came from, when it happened, how exactly severe the incident is. And the next thing is to troubleshoot it. And while most people usually do is access all their monitoring tools and platforms to try to understand and piece together where the issue and what the issue is. To try to find the root-cause and fix the issue. So, it might be going to your law aggregation system going to Kubernetes to check what’s happening with the post. Is everything healthy or is everything or something just crashing? Going to review Metrics and dashboards on your Datadog or Prometheus system. Checking your CI. Maybe somebody pushed a change and something was deployed. I don’t know.
Or: Yeah. There were propagated as an update into something like Opal.
Mickael: Yeah. For example, there are maybe some incidents that I find myself with 20 browser tabs open with a multitude of different tools trying to understand the piece together what happened what is the root cause of that thing.
Or: Right.
Mickael: And at Komodor that’s what we experience a lot of years working at different companies and what we’re trying to solve today, of bringing a unified view of audio services and systems into one system basically.
Or: Right.
Mickael: One system that can show you exactly what happened from services, from GitOp, Kubernetes and PagerDuty, Datadog, all of that. And show you an exact timeline of What’s happened that’s triggered something on another service and causes your application basically to be down or have high latency or any kind of other incident. I think the most important part when troubleshooting is understanding how something affected your application. It might be easy to find a log or some kind of dashboard that shows you this is bad. It’s easy to see. Okay, this is bad but what is bad?
Or: Right.
Mickael: What exactly happened? Who did it? Why did it happen? That’s all kind of questions that may take you I don’t know 2, 3, 4 hours to understand.
Or: Which can be very costly hours when it’s 2 o’clock at night.
Mickael: Yeah. Think of maybe you’re running a credit card or payment solution. If you’re down for 2 hours that can go up to millions of dollars.
Or: Right.
Mickael: These incident times are critical. You might have also the need to stay with some kind of SLA that you agreed on with your customers.
Or: Right. And then you get fined for not being on time.
Mickael: Exactly.
Or: Yeah.
Mickael: Yeah. So, what you might be able to see in Komodor is, first of all, kind of a service catalog that shows you exactly the state of your cluster or audio applications in one place.
Or: So, for example, in that, if I implement authorization, so I have like, I’ll be able to see my microservice for authorization, OPA for example.
Mickael: Exactly. You’ll see audio services including audio sidecars and authorization services. And if you want to try to deep dive on one specific thing because it’s currently not healthy you’re pressing, you’re not walking properly, then you’ll be able to see all the changes that happen up until this point with a connection to all your third parties that you’re using. Bringing everything into one view. And making it easier for you to understand what happened in your authorization services. What changed? Or who gave permission to somebody? Maybe you know, you, even as a developer, you’re trying to get access to some system to troubleshoot something and it works but the next minute it doesn’t. While you were, your access revolt.
Or: Yeah and here maybe I’ll connect those kinds of two dots. Now when you change things in the authorization so that’s changing code. And that code can affect the entire system and that can be because we needed to change in real-time, it changes in real-time. So, we need a way to keep track of it.
Mickael: Yeah. As you said with GitOps that you have everything is policy as code and everything is kind of automated. So, you have a code change. You have a CI or kind of automation that pipeline, deploys that change.
Or: Right.
Mickael: And you have your service that is being changed. There’re certainly three steps instead of one.
Or: Yeah. And there are multiple layers, multiple solutions. So, as we said before, you need the best practice of tagging everything. You want to write everything down in the market but even after your market, you need a way to have a kind of a single pane of glass. Yeah. Where you can see it all together.
Mickael: Exactly.
Or: Cool. So, obviously, people can try and build it but with Komodor, it kind of that’s what you do.
Mickael: I think every company tries and build something like that.
Or: Right.
Mickael: The issue is that it’s kind of a capacity issue that it takes a long time to have something that is polished and good enough for your company in your use case when troubleshooting. And it’s only as hard to do it.
Or: And you have like correct me if I’m wrong, like in Komodor you have a lot of knowledge built into the system. It knows common issues so it helps you find them.
Mickael: Yeah, so that’s one of the things that we do is that we don’t just bring you all the data into one place, we try to give you insight on what is happening and help you out. Trying to bridge the knowledge gap that some developers might have in difference with DevOps that might know more about the infrastructure and all the automation that’s going on in the system. For example, something is crashing. It’s nice to see that it’s not working but you want to understand exactly what is causing that.
Or: Yeah, makes sense. It makes total sense. So, we should probably start wrapping up. So, let’s do kind of a quick summary of what we talk about today. So, we talked about the different challenges that come with trying to write permissions and access control for modern applications. So, just the fact that it’s cloud-native makes it harder and we should be aware of that. It’s not the same thing as building authorization or monologues.
Mickael: Yeah.
Or: And we talked about how the data plane and the different multiple layers that we have make it more complex. And we talked about, what else we talk about? Help me kind of do the summary.
Mickael: We talk about all kinds of people or tenants that might be using your system and platform, your authorization. We talked about how to track, monitor, log, and audit your system the right way.
Or: Right. So, now it’s working differently and it has all those multiple layers. So, now we need to think about how we do logging and audit logs in advance when we’re building this.
Mickael: Yeah. And to summarize all that, I think the title that you talked about earlier is a perfect metaphor for that. Is trying to keep the right balance between somebody having too much access and somebody not knowing enough.
Or: Yeah, not having enough access to be able to even solve the problems in the system. So, these are all things that we kind of covered that are challenging when we’re building permissions for cloud additive applications and especially when we’re trying to troubleshoot them.
Mickael: Yeah.
Or: So, we need to be aware of them from day one. That’s one lesson we kind of learned today.
Mickael: The second lesson is what we do to improve all of that?
Or: Yes.
Mickael: And first of all, the decoupling policy and code making everything separate and unified is a lot simpler on your system and on you.
Or: Yeah. So, you want to have the code for authorization separate from your core logic for your application. If you do that, you already save a huge percentage of the pay. Then, you want to be able to update that in real-time. You want to be able to do those updates. It is connected to a GitOps process. You want to be able to build interfaces on top of those processes.
Mickael: You want to be able to do all of that. You need to start with building all of that with troubleshooting in mind. How to build all of that, so it becomes easier for you to understand troubleshoot. And one of that is adding quality information. As part of tags, annotation and labels basically as many spaces as you can think of. If it would be logs or coordinated resources or your authorization configuration, everything needs to be with quality information.
Or: Yeah. So, for our viewers, we have our slides both with the problems that we listed and the best practices. And also, you’re welcome to approach both myself and Michael. To ask more about it, you can join our select community for Opal and you can contact their contact sheets on Komodor’s website. Yeah and so we mentioned the pains, best practices on how to address them and we also mentioned tools. So, we have open source solutions like OPA and Opal and you also, obviously, kind of maybe we mentioned it too much, but you also have tools that kind of help you build this end to end, authorize them. They can give you full-stack authorization end to end and Komodor that can give you the entire troubleshooting end to end.
Each one of you can kind of choose the right balance for you. But if you know the problems and you know the best practices, you can now decide how you wanna go about approaching them and not wake up in the middle of the night realizing that you have a gaping hole that you didn’t take care of.
Mickael: That is the rule.
Or: Yeah, awesome. Michael, thank you very much. It was a pleasure doing this webinar with you.
Mickael: Me as well.
Or: And thank you everyone for watching.
Mickael: Yeah. So, I think we’re ready for some questions if we’re out from the audience.
Udi: Yeah. So, thank you both. This was super interesting and thank you for that. So, we only have a couple of questions. So, I’m guessing that you are so informative and on point that nobody has any more to ask. So, one question is, can Komodor and Authorizon integrate together? How do you integrate permission control with Komodor?
Mickael: Right. So, I can answer that one.
Or: Yeah, go for it.
Mickael: Komodor offers in addition to all the integration we do support officially we do have a rest API, that you can integrate with any kind of integration also to Authorizon. And send us that about what changed and what it is connected to, and we’ll be able to show it along with your service.
Or: Yeah. So maybe to double click on that. So even not just Authorizon, both are open-source, Opal. So, Opal has part of it a pop up channel that creates those updates. It essentially creates an event for every change in the authorization there. And then you can tell it to push data or updates into whatever socials you can have Opal notify Komodor of changes in the authorization there.
Mickael: Which is a great use case.
Or: Yeah. So, every time something changes you can let Komodor know and that can become your kind of the main view on what’s happening. In general, by having an event-driven channel, you can track things better and when you have a unified single panel glass, it’s easier to track.
Mickael: Yeah.
Or: next question.
Udi: Another question we have from Victoria. She’s asking, how is Comodo different from Kubectl? Why can’t I just use Kubectl to troubleshoot?
Mickael: Well, Komodor offers you also kind of a view of Cube CTL. The difference is that not all developers or employees might have access to Kubectl. And that becomes a big issue. That’s why we talked about the tight-rope
Or: Mm-hmm.
Mickael: You want people to see data. You don’t want to give them too much access into production systems.
Or: Right. So, it’s like the recursive aspect of authorization that we’re touching up here.
Mickael: Yeah but I think on top of that what we do offer is also kind of a simpler view for people that don’t necessarily have a lot of Kubernetes knowledge to understand their system with Komodor along with obviously a lot of integrations that are on top of that.
Or: Yeah. It essentially touches on the kind of best practice of interfaces in the back office.
Mickael: Yeah.
Or: You don’t only have developers. You have developers, DevOps, product managers, security, professional services. Each of them needs different tools. Now, all of them can work with Kubctl. Like, even you won’t even give like a fountain engineers and feed the Kubectl. It’s not the right tool for them.
Mickael: It might have the access but it doesn’t have to use it.
Or: Exactly. So, you need a more tailored solution for each one.
Udi: And also, correct me from around Mickael but the history on Kubectl, I mean, can Kubectl shows you like the history of all the changes or is it always something you can do with a tool like Komodor?
Mickael: So, there are some tools that offer you kind of histories and provisions. Kubectl itself does not give you any kind of history. If you use Helm or Argo CD or other kinds of CI/CD tools, they might offer you history, but in kind of a low way which is really hard to understand troubleshoots from.
Or: Make sense.
Udi: Good and last question we have and I think this goes to you Or.
Or: Okay.
Udi: How does, sorry is Authorizon offering an end-to-end solution. Is it something that you can just copy-paste?
Or: Yeah, so that’s essentially the idea. So, unlike the different building blocks that you can use like OPA and OPAL that you can build on your own with Authorizon. The idea is that we cover you and events. We give you both the infrastructure, the back office and interfaces that you need and for your own management and what you need for your customers. So, you get both things like an SDK that you can embed into your code and do like is allowed, who can do what. You can do an implementing enforcement point. And you can do on the other hand, you can do have a policy editor that your product manager can work with this side who has access to what in a kind of a local, no-good fashion. And your users get an interface that you can embed in like a wireframe or React component or you can connect with the API. They can get like a user management table where they can invite themselves and invite every user to assigned roles and you can get all of that working and you just need to copy-paste lots of code. You don’t need to think about how you connect everything because we do that lift up for you.
Udi: Amazing. We don’t have any further questions, so good job guys. Do you have anything else to add before we wrap this up?
Or: I had a lot of fun and looking forward to doing another event with you guys.
Mickael: Yeah. Thank you so much for watching.
Or: Thank you, Mickael.
Udi: Alright guys. So, thank you everyone for joining us and we’ll see you on our next event.
Or: Bye everyone.
Udi: Bye-bye.