
The Autonomous AI SRE Platform
for Your Cloud-Native Infrastructure
Trusted in production by the world's most demanding cloud-native enterprises

The Power of Kubernetes and Cloud Native
Minus the Complexity
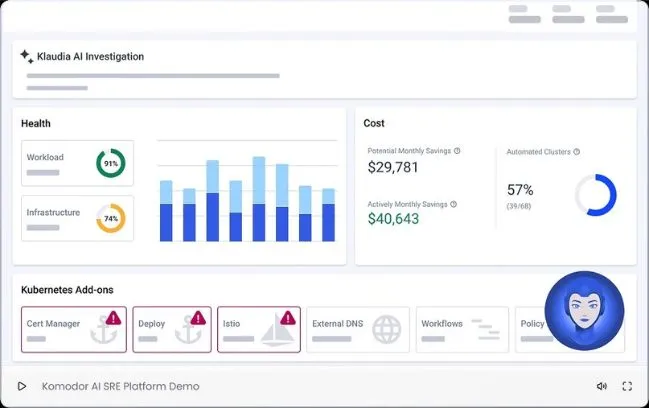
Visualize
Consolidate multi-cluster, cloud, and hybrid estates in curated, contextual workspaces. Empower engineers, data scientists, and experts to instantly understand status, change history, dependencies and insights.
Try NowTroubleshoot
Automatically detect, investigate, and remediate any issue across the most complex cloud-native environments. Slash MTTR to just seconds with battle-tested, AI-driven root cause analysis, one-click fixes and autonomous self-healing.
Test DriveOptimize
Turbocharge Kubernetes cost efficiency with dynamic right-sizing, constraint-aware bin-packing and intelligent pod placement. Extend autoscalers with predictive intelligence, smart scaling, and zero-downtime workload migration.
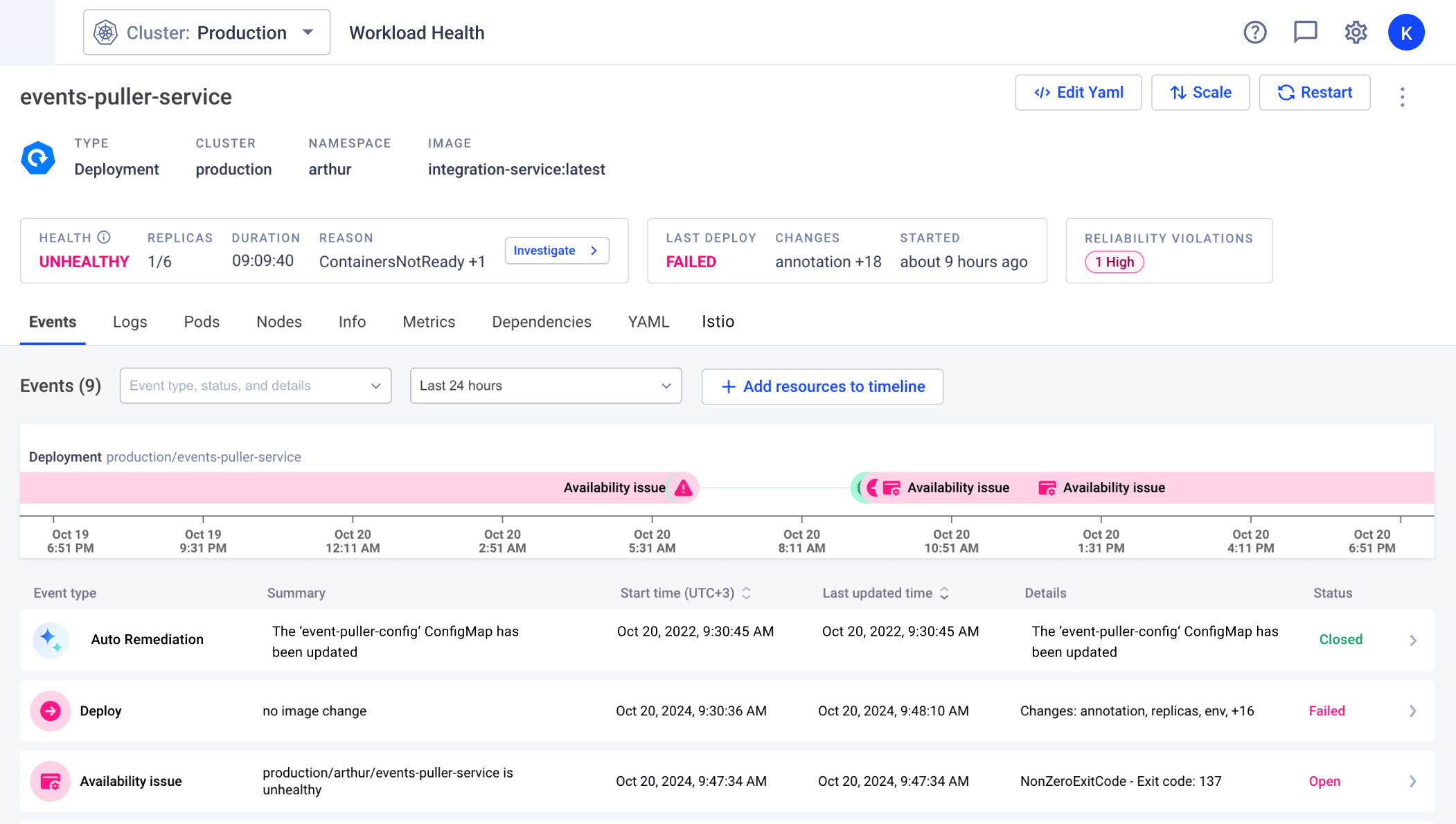
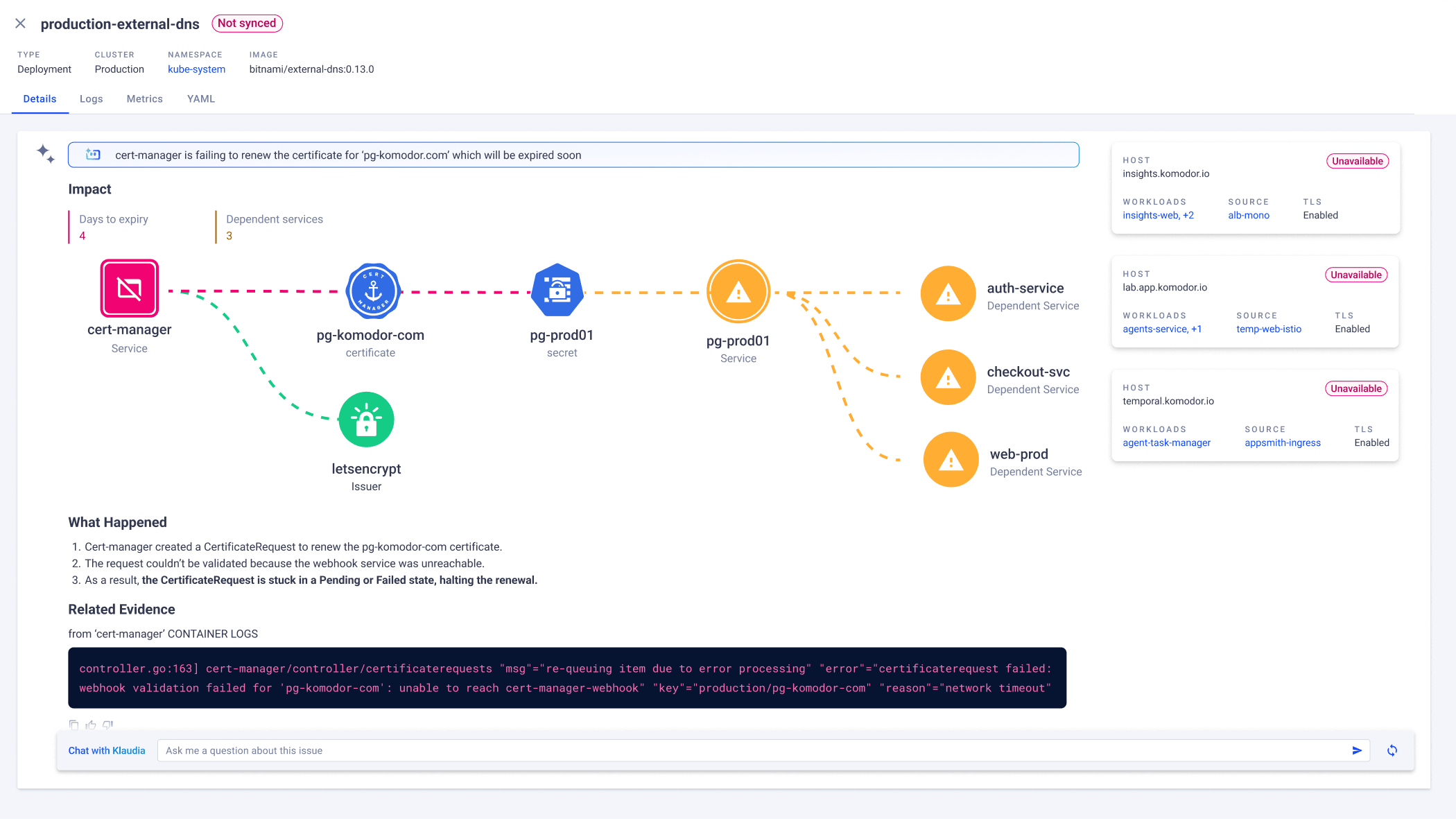
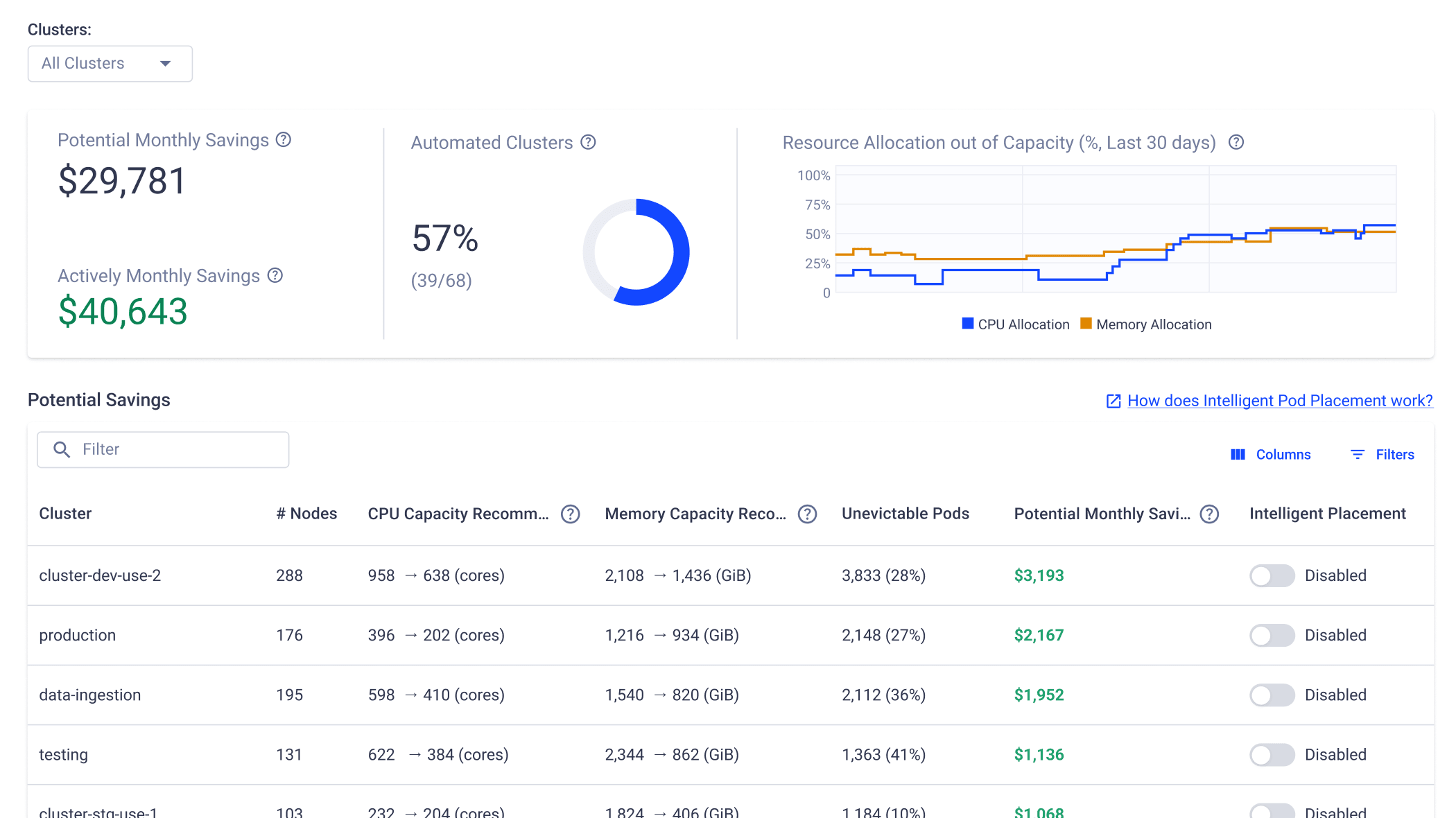
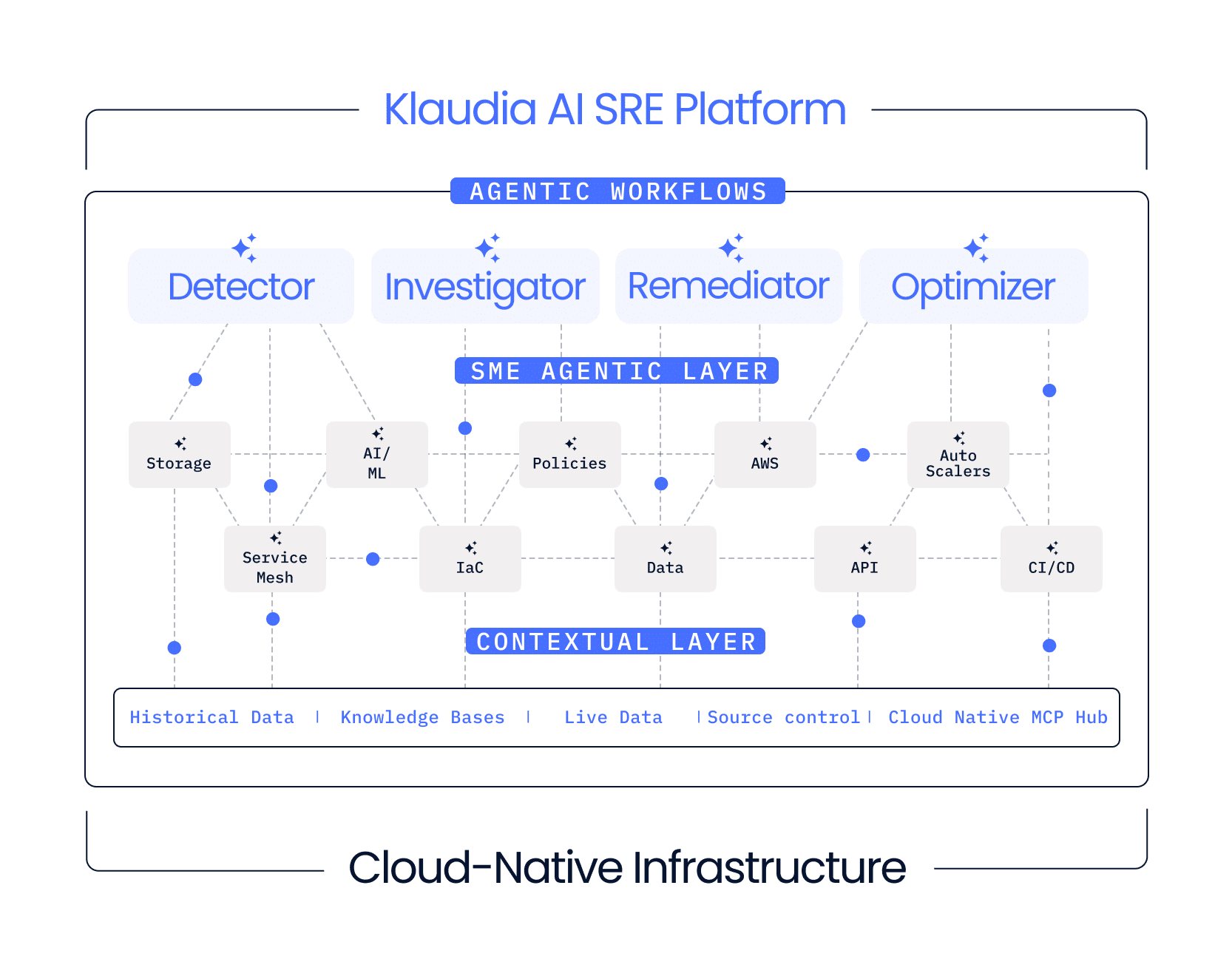
Not Another AI SRE Assistant
- AI SRE (AI Site Reliability Engineering) is an autonomous approach to reliability that detects, investigates, and resolves production issues without manual intervention.
- Powered by Klaudia Agentic AI, Komodor brings AI SRE to life, rapidly resolving complex cloud-native incidents.
- Covers scenarios such as failed containers, cascading errors, faulty add-ons, CRDs, and workload breakdowns.
- Built on hundreds of specialized AI agents trained across thousands of real-world production environments.
- Proven in production, delivering up to 95% accuracy in incident detection and resolution.
| Komodor AI SRE Platform | AIOps / Traditional SRE Tools | |
| Incident Detection | Automatically detects anomalies in real time using AI agents | Relies on alerts, thresholds, and manual monitoring |
| Root Cause Analysis | Autonomous investigation across services, configs, and dependencies | Manual correlation across multiple tools and dashboards |
| Resolution | Suggests or executes remediation actions automatically | Requires manual troubleshooting and playbooks |
| Noise Reduction | Correlates signals to reduce alert fatigue and false positives | High alert noise with limited context |
| Learning & Adaptation | Continuously learns from past incidents and environments | Static rules and predefined thresholds |
| Time to Resolution (MTTR) | Significantly reduced through automation and guided remediation | Slower due to manual investigation and fragmented tooling |
| Kubernetes & Cloud-Native Coverage | Deep, context-aware visibility across Kubernetes and cloud-native stack | Partial visibility across siloed tools |
| Operational Efficiency | Reduces engineering toil and operational overhead | High manual effort and operational cost |
Komodor Delivers Proven ROI
Cut Down
In Kubernetes compute costs
Resolve
Production
incidents
Save
Engineering
Hours
Reduce
Tickets & SRE escalations
