[BASED ON A TRUE STORY]
It’s a cold gloomy night, and Sarah, a full-stack Web developer, is doing her third on-call shift this week. The wind howls outside as Sarah tosses and turns in her bed, her dreams troubled by horrific visions of blaring alerts and cascading incidents from the previous shift.
The clock struck three and Sarah’s worst fears materialized, as she woke up to a sound she knows all too well – a sound that she has learned to dread. The sound of a PagerDuty alert.
With a sinking heart, Sarah draws a heavy breath and rubs the sleep off of her eyes. In her mind, she can already imagine the night ahead of her. Sitting alone in the darkness of her room, face illuminated by the light of the laptop screen, manually searching through countless k8s diffs, not knowing who changed what and when.
It’s a bad place to be in, and sadly, she has been there many times before, oftentimes working for several long hours before giving up and waking the next person up the flagpole, all the way to the head of DevOps…
But not this time.
Suddenly a second Slack message appears. It’s from a new service called Komodor. In the message, Sarah can see the affected service and the latest relevant events, pointing her in the right direction.
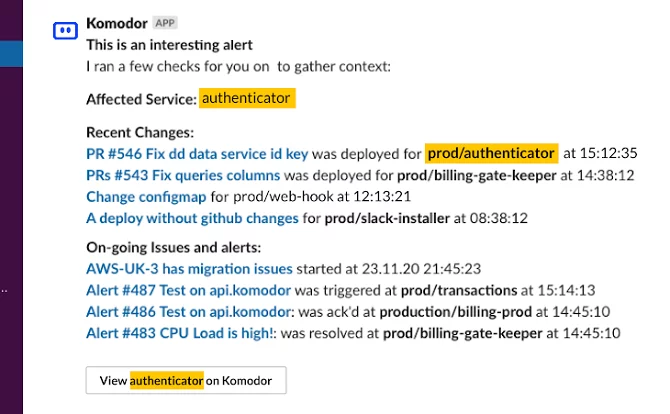
She follows the link below. Switching to Komodor, she can now see the entirety of the service’s activity, including related services, events from K8s, Github, Datadog and config changes.
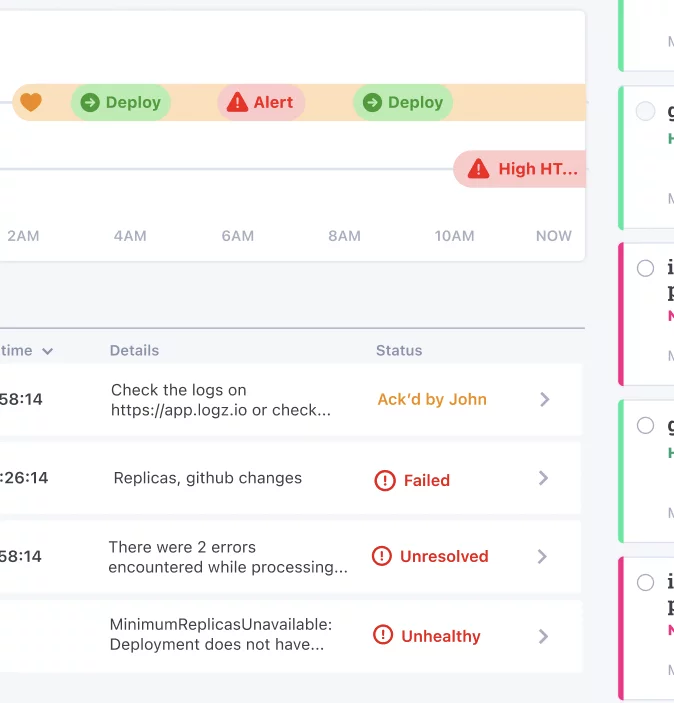
Looking into the deploy, Komodor displays the main changes and allows easy access to the relevant diffs. Here Sarah can see all the changes to the system, and their ripple effects, in a single coherent timeline.
Using the timeline view, Sarah noticed that a change to the system that occurred just a moment before the service became unhealthy. This obviously gets her attention, but she knows better than to jump to any quick conclusions. No, she needs to dive deeper to know for sure that it is the root cause – and so she does.
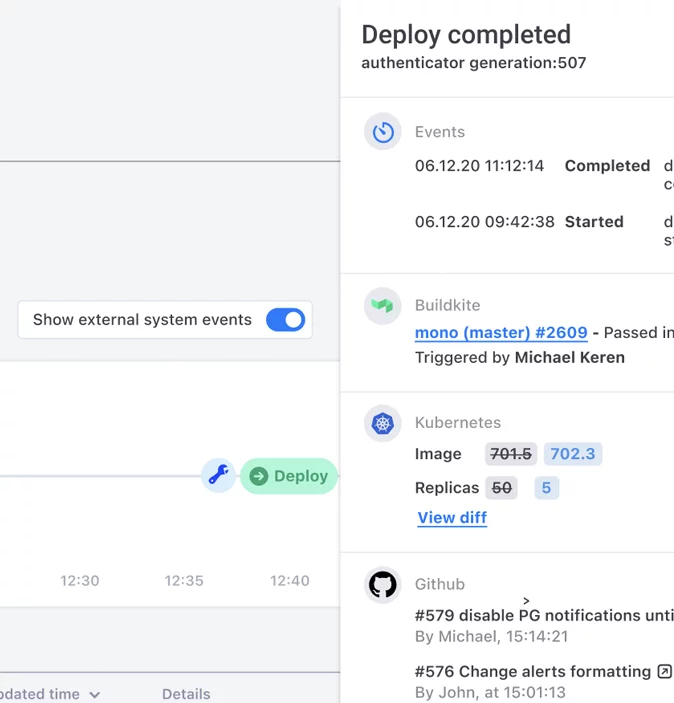
With the help of Komodor Sarah reviews the k8s diff to see exactly what changed, and finds a latency in one of the services. She sees that the service used to have 50 replicas, but now has only 5, which is most likely the reason behind the service’s declining health.

Solution time!
Sarah decides to scale up the service back to 50 replicas and uses the quick actions option to easily follow through.
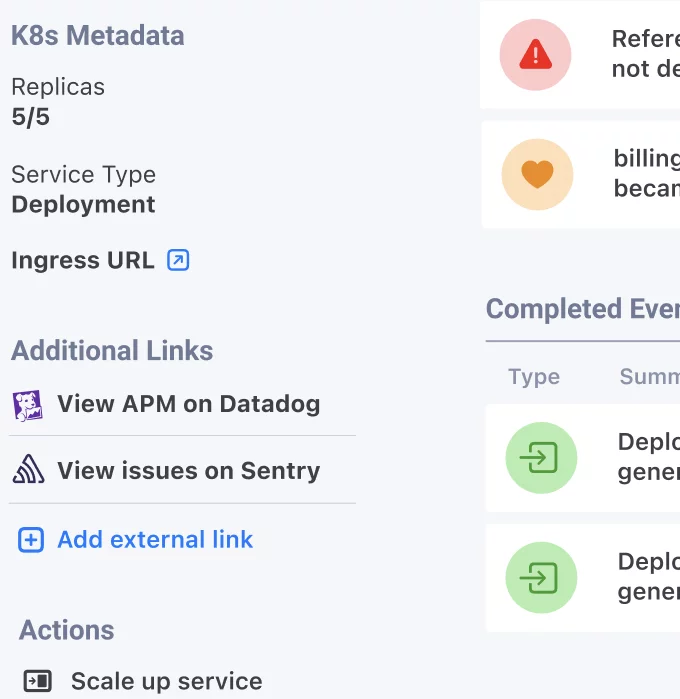
And just like that, with only two clicks the issue is resolved, the service’s health meter is up again, and Sarah can go back to sleep, safe in the knowledge that no matter what other incidents may come her way on this dreary night, Komodor has got her back.


