What Is CPU Throttling in Kubernetes?
Kubernetes CPU throttling means that applications are granted more constrained resources when they are near to the container’s CPU limit. In some cases, container throttling occurs even when CPU utilization is not close to the limit, due to bugs in the Linux kernel. It’s important to monitor for, and try to avoid, throttling whenever possible.
Consider a single-threaded application running on a limited CPU with a processing time of 200ms per operation. The following diagram shows an application that completes the request:
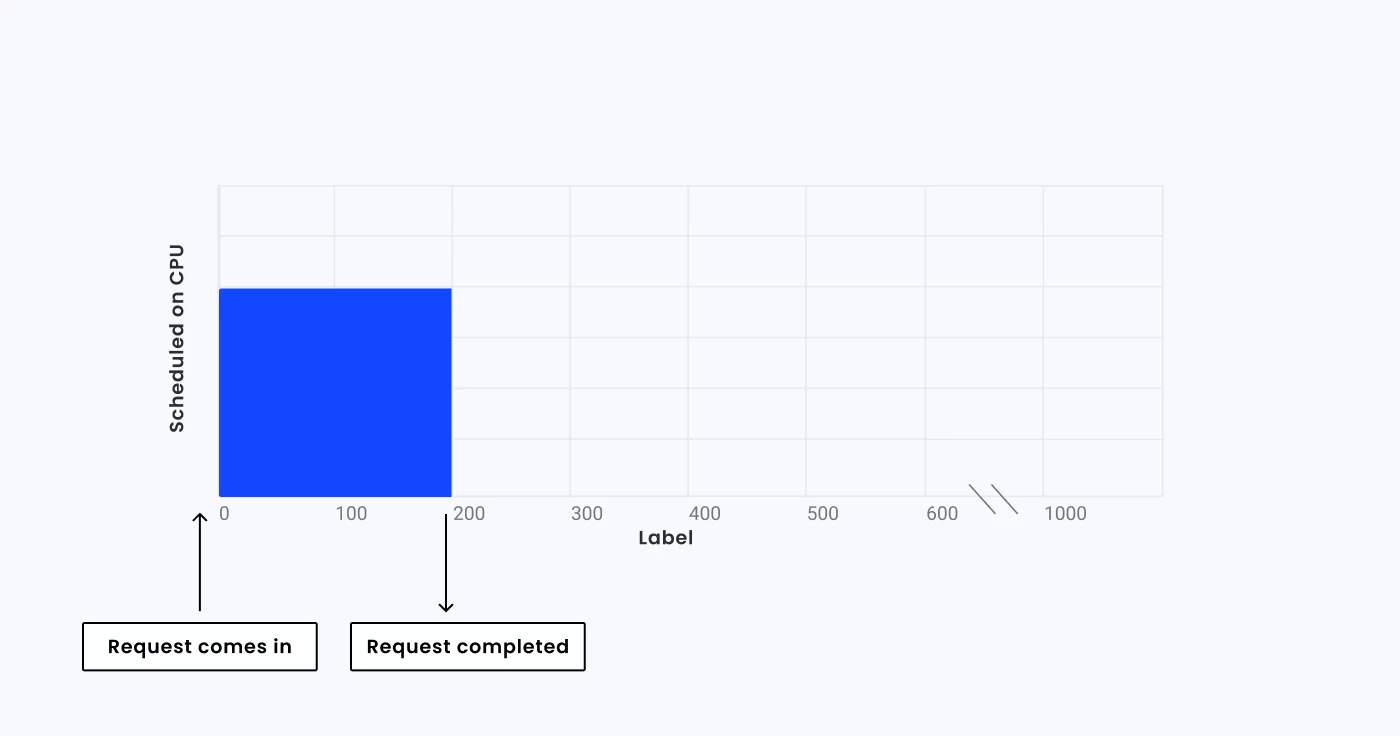
Now consider an application with a CPU limit of 0.4 CPUs. The application will only receive about 40ms of runtime for each 100ms. This means that instead of completing the request in 200ms, it will take a total of 440ms. This means the application is experiencing CPU throttling.
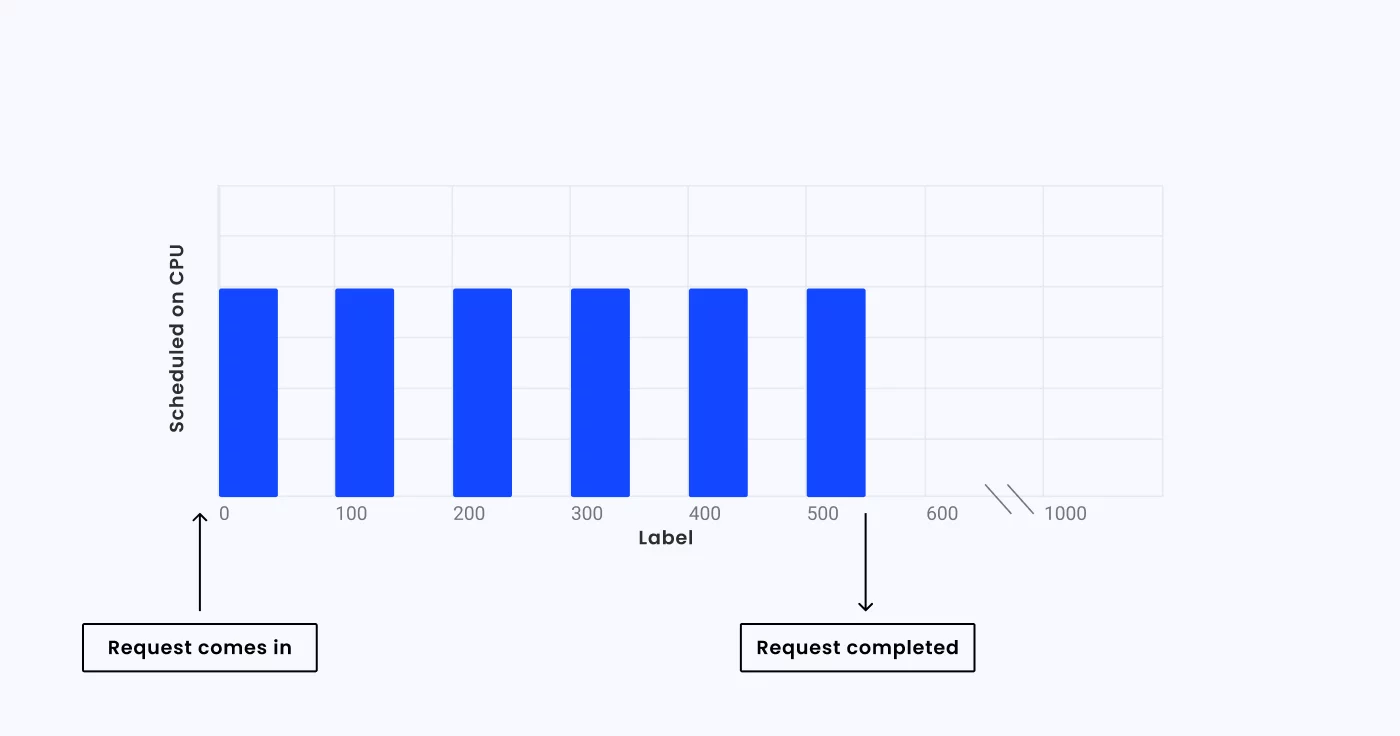
Why Does Kubernetes CPU Throttling Matter?
There are several issues that can be caused by CPU throttling in Kubernetes, which makes it important to monitor for and avoid throttling as much as possible.
Degraded Performance
When an application hits its CPU limit, it is throttled, meaning its CPU usage is artificially reduced. This can cause significant delays in processing tasks. For applications that require consistent and high performance, throttling can lead to unacceptable performance degradation.
Increased Latency
Latency is the time taken for a request to be processed and a response to be returned. When the CPU is throttled, it lengthens the time needed to complete each request. Increased latency can lead to timeouts and failed transactions. In extreme cases, it might cause cascading failures where one slow component delays others, leading to system-wide performance issues.
Resource Inefficiency
When containers are throttled, they may not be utilizing their allocated CPU resources effectively. This can result in a scenario where CPU resources are underutilized while applications are still experiencing performance issues. This inefficiency can lead to higher operational costs as more resources are allocated than necessary to compensate for throttling.
Tips from the expert

Itiel Shwartz
Co-Founder & CTO
In my experience, here are tips that can help you better manage and avoid Kubernetes CPU throttling:
Analyze historical usage
Review historical CPU usage patterns to set more accurate requests and limits, minimizing the risk of throttling.
Use vertical pod autoscaling (VPA)
Implement VPA to dynamically adjust CPU requests and limits based on real-time usage.
Prioritize critical workloads
Assign critical workloads to the Guaranteed QoS class to ensure they receive consistent CPU resources.
Implement node-level isolation
Use taints and tolerations to isolate critical workloads on dedicated nodes to avoid interference from other pods.
Monitor kernel bugs
Stay updated on and apply patches for Linux kernel bugs that could cause unexpected CPU throttling.
CPU Throttling in Action: Practical Example
To understand how CPU throttling works in practice, let’s walk through a scenario using Kubernetes.
Setting Up a Kubernetes Deployment
First, create a Kubernetes deployment with a specific CPU limit. The following YAML file defines a deployment for an application with a CPU limit set to 0.4 CPUs:
apiVersion: apps/v1
kind: Deployment
metadata:
name: throttled-app
spec:
replicas: 1
selector:
matchLabels:
app: throttled-app
template:
metadata:
labels:
app: throttled-app
spec:
containers:
- name: throttled-app
image: your-application-image:latest
resources:
limits:
cpu: "0.4"
requests:
cpu: "0.2"
Apply this deployment using kubectl:
kubectl apply -f throttled-app-deployment.yaml

In order to simulate stress on the CPU, we will use the Ubuntu stress package on Ubuntu. Run kubectl get pods, get the name of the pod, then SSH into the kubernetes pod using the command kubectl exec -it <pod-name> -- /bin/bash

Now you can install the stress package on the pod as follows:
Observing CPU Throttling
We’ll simulate the load on the CPU using the stress module, by running the command stress --cpu 60

Now you can observe CPU throttling by monitoring the CPU usage of the container. Use the kubectl top command to see real-time CPU usage:
kubectl top pods -l app=throttled-app

You might notice that the CPU usage occasionally hits the specified limit, indicating that the application is being throttled. To further analyze the issue, you can inspect the CPU throttling metrics provided by the Kubernetes metrics server or a monitoring solution like Prometheus.

Example of Throttling in Logs
If you have detailed logging enabled for your application, you might see increased processing times when the application is throttled. Here’s a simplified log snippet that might show this:
2024-05-30 10:00:00 INFO Processing request ID 1234
2024-05-30 10:00:01 INFO Request ID 1234 processing completed in 200ms
2024-05-30 10:00:02 INFO Processing request ID 1235
2024-05-30 10:00:02 WARNING CPU throttling detected
2024-05-30 10:00:03 INFO Request ID 1235 processing completed in 440ms
The log indicates that when CPU throttling occurs, the processing time for requests increases significantly.
4 Ways to Detect and Avoid CPU Throttling in Kubernetes
Here are some of the ways you can minimize CPU throttling in Kubernetes.
Understand Resource Requests and Limits
Resource requests determine the minimum amount of CPU resources guaranteed for a container, while limits set the maximum resources it can use. Misconfigurations can lead to either resource starvation or over-provisioning. It’s important to monitor the actual resource usage of your applications and adjust requests and limits accordingly.
Tools like Kubernetes Metrics Server and Prometheus can help you track CPU usage patterns and make informed decisions about resource allocation. By fine-tuning these parameters, you can minimize the likelihood of CPU throttling and ensure that your applications have enough resources to perform adequately without wasting them.
Use Resource Quality of Service (QoS) Classes
Kubernetes uses Quality of Service (QoS) classes to prioritize resource allocation for pods. There are three QoS classes: Guaranteed, Burstable, and BestEffort. Assigning the correct QoS class based on the application’s requirements can help manage CPU throttling:
- Guaranteed: Pods have both CPU requests and limits set to the same value, ensuring they receive the exact amount of resources they need, thus avoiding throttling.
- Burstable: Pods have CPU requests less than their limits, allowing them to utilize extra resources when available, but they may be throttled when the node is under pressure.
- BestEffort: Pods with no resource requests or limits, which makes them the first to be throttled during resource contention.
Leverage Horizontal Pod Autoscaling
Horizontal Pod Autoscaling (HPA) can automatically adjust the number of pod replicas in a deployment based on observed CPU utilization or other select metrics. By scaling out (adding more pods) when CPU usage is high, HPA can distribute the load across more instances, reducing the likelihood of any single pod being throttled.
To implement HPA, you define a target CPU utilization percentage, and Kubernetes automatically adjusts the number of replicas to maintain this target. This dynamic scaling helps maintain performance and responsiveness, especially under varying load conditions.
Utilize Kubernetes Monitoring Tools
Kubernetes monitoring tools can provide insights into CPU usage, throttling events, and overall cluster health. Setting up dashboards to visualize these metrics can help you identify patterns and potential issues before they impact your applications.
Additionally, you can configure alerts to notify you when CPU throttling exceeds acceptable thresholds, allowing you to take corrective action promptly. By continuously monitoring your Kubernetes environment, you can ensure optimal resource utilization and minimize performance degradation due to CPU throttling.
Solving Kubernetes Node Errors with Komodor
Troubleshooting Kubernetes CPU issues requires visibility into Kubernetes cluster node, and the ability to correlate node status with what’s happening in the rest of the cluster. More often than not, you will be conducting your investigation during fires in production.
Komodor can help with its ‘Node Status’ view, built to pinpoint correlations between service or deployment issues and changes in the underlying node infrastructure. With this view you can rapidly:
- See service-to-node associations
- Correlate service and node health issues
- Gain visibility over node capacity allocations, restrictions, and limitations
- Identify “noisy neighbors” that use up cluster resources
- Keep track of changes in managed clusters
- Get fast access to historical node-level event data
Beyond node error remediations, Komodor can help troubleshoot a variety of Kubernetes errors and issues. As the leading Continuous Kubernetes Reliability Platform, Komodor is designed to democratize K8s expertise across the organization and enable engineering teams to leverage its full value.
Komodor’s platform empowers developers to confidently monitor and troubleshoot their workloads while allowing cluster operators to enforce standardization and optimize performance. Specifically when working in a hybrid environment, Komodor reduces the complexity by providing a unified view of all your services and clusters.
By leveraging Komodor, companies of all sizes significantly improve reliability, productivity, and velocity. Or, to put it simply – Komodor helps you spend less time and resources on managing Kubernetes, and more time on innovating at scale.
Related content: Read our guide to Kubernetes RBAC
If you are interested in checking out Komodor, use this link to sign up for a Free Trial.


